Appearance
MIT 6.S081 Lab System calls 补充内容
- RISC-V的三种特权模式
- 宏内核 vs. 微内核
- xv6中的进程
- 系统调用的流程
RISC-V的三种特权模式
| 特权模式 | 功能描述 |
|---|---|
| 机器模式(M-mode) | 具有最高特权等级,具有访问所有资源的权限,通常运行固件和内核 |
| 管理员模式(S-mode) | 权限要比M模式低,通常是用来运行操作系统内核 |
| 用户模式(U-mode) | 级别最低的模式,它不能访问硬件资源,只能访问某些通用寄存器和通用指令,一般用于执行应用程序 |
三种特权模式之间的切换:
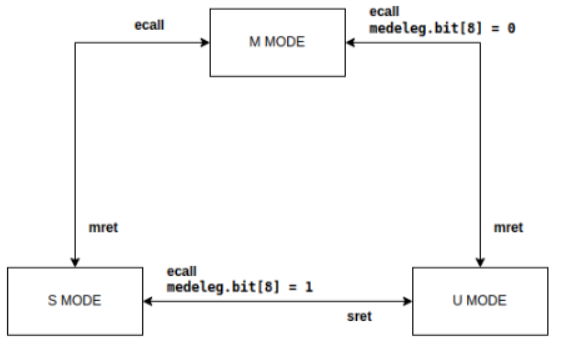
- 从user mode切换到supervisor mode,调用
ecall指令 - 从supervisor mode切换到user mode,调用
sret指令
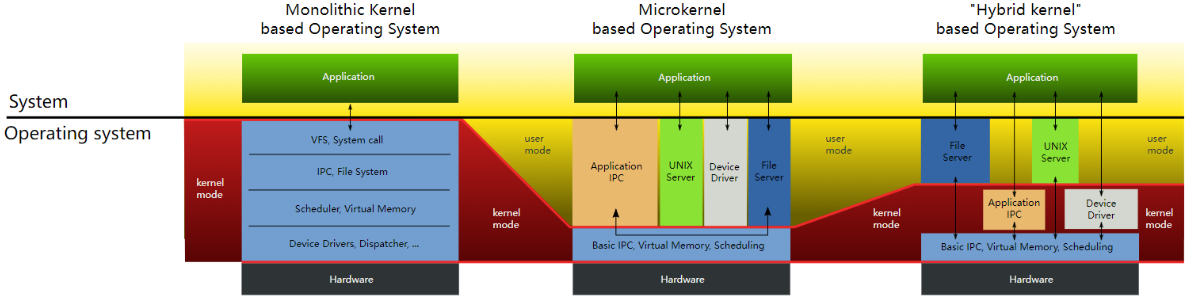
宏内核 vs. 微内核
monolithic kernel:整个操作系统在kernel中,所有system call都在supervisor mode下运行。
xv6是一个monolithic kernel
micro kernel:将需要运行在supervisor mode下的操作系统代码压到最小(cpu调度、内存管理和进程通信),保证kernel内系统的安全性,将大部分的操作系统代码执行在user mode下。
xv6中的进程
这部分内容参考:第一章 第一个进程 | xv6 中文文档 (gitbooks.io)
进程是一个抽象概念,它让一个程序可以假设它独占一台机器(进程隔离)。进程向程序提供“看上去”私有的,其他进程无法读写的内存系统(或地址空间),以及一颗“看上去”仅执行该程序的CPU。
xv6 使用页表(由硬件实现)来为每个进程提供其独有的地址空间。页表将虚拟地址(x86 指令所使用的地址)翻译(或说“映射”)为物理地址(处理器芯片向主存发送的地址)。
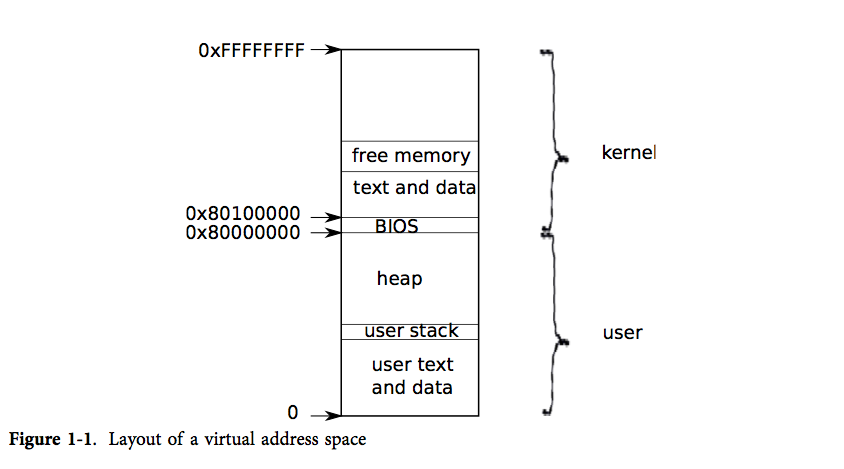
xv6 为每个进程维护了不同的页表,这样就能够合理地定义进程的地址空间了。如图表1-1所示,一片地址空间包含了从虚拟地址0开始的用户内存。它的地址最低处放置进程的指令,接下来则是全局变量,栈区,以及一个用户可按需拓展的“堆”区(malloc 用)。
xv6 使用结构体 struct proc 来维护一个进程的状态,其中最为重要的状态是进程的页表,内核栈,当前运行状态。我们接下来会用 p->xxx 来指代 proc 结构中的元素。
p->state 指示了进程的状态:新建、准备运行、运行、等待 I/O 或退出状态中。
创建进程时会调用allocproc ,在 proc 的表中找到一个标记为 UNUSED的槽位,将其状态设置为 EMBRYO,使其被标记为被使用的并给这个进程一个独有的 pid。接下来,它尝试为进程的内核线程分配内核栈。如果分配失败了,allocproc 会把这个槽位的状态恢复为 UNUSED 并返回0以标记失败。
因此,Lab2中nproc()方法统计proc中状态不为UNUSED的个数的实现如下:
uint64 nproc(void)
{
uint64 cnt = 0;
for(int i = 0; i < NPROC; i++){
if(proc[i].state != UNUSED) cnt++;
}
return cnt;
}每个进程都有用户栈和内核栈(p->kstack)。当进程运行用户指令时,只有其用户栈被使用,其内核栈则是空的。然而当进程(通过系统调用或中断)进入内核时,内核代码就在进程的内核栈中执行;进程处于内核中时,其用户栈仍然保存着数据,只是暂时处于不活跃状态。进程的线程交替地使用着用户栈和内核栈。要注意内核栈是用户代码无法使用的,这样即使一个进程破坏了自己的用户栈,内核也能保持运行。
Warning
进程的内核栈和用户栈分配的页表不同,所以相同逻辑地址其实是不一样的物理地址
(它们就像是在两个平行空间里)
Lab2中要将在内核中填完信息的sysinfo复制到指定的地址,但是这个地址是在用户空间的逻辑地址,所以完成这个操作要使用到copyout。
if(copyout(myproc()->pagetable, addr, (char *)&sinfo, sizeof(sinfo)) < 0)
return -1;myproc()->pagetable获取了当前进程的页表地址,addr是用户空间指定的逻辑地址,根据这两个信息可以得到物理地址,然后就可以将sinfo复制到物理地址中去。
系统调用的流程
这部分内容参考:[mit6.s081] 笔记 Lab2: System calls | 系统调用 | Miigon's blog
以Lab2的第一个实验为例:
user/user.h:用户态程序调用跳板函数trace()user/usys.S:跳板函数trace()使用 CPU 提供的 ecall 指令,调用到内核态- 由
user/usys.pl脚本生成的汇编文件
- 由
kernel/syscall.c:到达内核态统一系统调用处理函数syscall(),所有系统调用都会跳到这里来处理kernel/syscall.c:syscall()根据跳板传进来的系统调用编号,查询syscalls[]表,找到对应的内核函数并调用- 系统调用编号在
kernel/syscall.h中定义 - 在
kernel/syscall.c中需要用extern全局声明新的内核调用函数,并且在syscalls[]表中,加入从前面定义的编号到系统调用函数指针的映射
- 系统调用编号在
kernel/sysproc.c:到达sys_trace()函数,执行具体内核操作
这么繁琐的调用流程的主要目的是实现用户态和内核态的良好隔离。
并且由于内核与用户进程的页表不同,寄存器也不互通,所以参数无法直接通过 C 语言参数的形式传过来,而是需要使用 argaddr、argint、argstr 等系列函数,从进程的 trapframe 中读取用户进程寄存器中的参数。
同时由于页表不同,指针也不能直接互通访问(也就是内核不能直接对用户态传进来的指针进行解引用),而是需要使用 copyin、copyout 方法结合进程的页表,才能顺利找到用户态指针(逻辑地址)对应的物理内存地址。
struct proc *p = myproc(); // 获取调用该 system call 的进程的 proc 结构
copyout(p->pagetable, addr, (char *)&data, sizeof(data)); // 将内核态的 data 变量(常为struct),结合进程的页表,写到进程内存空间内的 addr 地址处。