Appearance
Copy-on-Write Fork for xv6
Lab: Copy-on-Write Fork for xv6 (mit.edu)
开启新实验
git fetch
git checkout cow
make cleanThe problem
xv6 中的fork()系统调用将父进程的所有用户空间内存复制到子进程中。如果父级很大,则复制可能需要很长时间。更糟糕的是,工作往往被大量浪费;例如,子项中的fork()后跟exec()将导致子项丢弃复制的内存,可能从未使用过其中的大部分内存。另一方面,如果父级和子级都使用一个页面,并且其中一个或两个都编写了它,则确实需要一个副本。
The solution
写入时复制 (COW) fork() 的目标是推迟为子项分配和复制物理内存页,直到实际需要副本(如果有的话)。
COW fork() 只为子项创建一个页面表,用户内存的 PTE 指向父项的物理页面。COW fork() 将父级和子级中的所有用户 PTE 标记为不可写。当任一进程尝试写入这些 COW 页面之一时,CPU 将强制出现页面错误。内核页面错误处理程序检测到这种情况,为错误进程分配一页物理内存,将原始页面复制到新页面中,并在错误过程中修改相关的 PTE 以引用新页面,这次将 PTE 标记为可写。当页面错误处理程序返回时,用户进程将能够编写其页面副本。
COW fork() 使得释放实现用户内存的物理页面变得更加棘手。给定的物理页可能被多个进程的页表引用,并且只有在最后一个引用消失时才应释放。
Implement copy-on write
Info
修改kernel/vm.c中的uvmcopy()以将父页面的物理页面映射到子页面,而不是分配新页面。清除父进程和子进程的PTE_W位。
int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
// char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
*pte &= (~PTE_W);
flags = PTE_FLAGS(*pte);
// if((mem = kalloc()) == 0)
// goto err;
// memmove(mem, (char*)pa, PGSIZE);
if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
// kfree(mem);
goto err;
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}Info
修改kernel/trap.c中的usertrap()来处理缺页错误。如果缺页错误发生在 COW 页上,就分配一个新的物理页,拷贝原页帧的数据到新页,并设置新页的 PTE_W。
对于每个 PTE ,需要有一种方法来记录是否是 COW 页。为此可以使用 RISC-V PTE 中的 RSW(为软件保留)位。

RSW 是第8和第9位,所以可以选择第8位来记录是否为 COW 页。在kernel/riscv.h中添加:
#define PTE_C (1L << 8)还需要对步骤一kernel/vm.c中的uvmcopy()进行修改,将 PTE_C 置1。
...
*pte &= (~PTE_W);
*pte |= PTE_C;
...这时就可以写个函数判断是否是 COW 页了:
int uncopy_cow(pagetable_t pgtbl, uint64 va)
{
if(va >= MAXVA) return 0;
pte_t *pte = walk(pgtbl, va, 0);
if(pte && (*pte & PTE_V) && (*pte & PTE_U))
return (*pte & PTE_C);
return 0;
}接下来如何判断发生了缺页错误呢?
根据 riscv 的文档:

scause 为 15 代表尝试写入引发的缺页错误。
判断逻辑如下:
...
} else if(r_sause() == 15 && uncopy_cow(p->pagetable, r_stval())){
// 处理
} else {
...确定当前页是合法的 COW 页之后,就需要给这个 COW 页分配物理内存,同样写一个函数封装。
int cowalloc(pagetable_t pgtbl, uint64 va){
pte_t* pte = walk(pgtbl, va, 0);
uint64 perm = PTE_FLAGS(*pte);
if(pte == 0) return -1;
uint64 oldpage = PTE2PA(*pte);
uint64 newpage = (uint64)kalloc();
if(!newpage) return -1;
uint64 va_sta = PGROUNDDOWN(va); // 当前页帧
perm &= (~PTE_C);
perm |= PTE_W;
memmove((void*)newpage, (void*)oldpage, PGSIZE); // 复制
uvmunmap(pgtbl, va_sta, 1, 1); // 取消对父进程页帧的映射
// 重新映射
if(mappages(pgtbl, va_sta, PGSIZE, (uint64)newpage, perm) < 0){
kfree((void*)newpage);
return -1;
}
return 0;
}类型转换你要不杀了我吧。
最终在kernel/trap.c的usertrap()中进行如下修改:
...
} else if(r_sause() == 15 && uncopy_cow(p->pagetable, r_stval())){
if(cowalloc(p->pagetable, r_stval()) < 0){
p->killed = 1;
}
} else {
...Info
确保每个物理页面在对它的最后一个 PTE 引用消失时被释放——而不是在此之前。执行此操作的一个好方法是为每个物理页面保留引用该页面的用户页面表数量的“引用计数”。
当 kalloc()分配页面时,将页面的引用计数设置为 1。当 fork 导致子进程共享页面时增加页面的引用计数,并在每次任何进程从其页面表中删除页面时减少页面的计数。kfree() 只有在其引用计数为零时才应将页面放回空闲列表。
可以将这些计数保存在固定大小的整数数组中。必须制定一个方案来说明如何索引数组以及如何选择其大小。例如,可以索引该数组,将页面的物理地址除以 4096,并为数组提供等于 kalloc.c 中 kinit() 放置在空闲列表上的任何页面的最高物理地址的元素数量。
可以在kernel/kalloc.c中添加如下的宏:
#define PG2REFIDX(_pa) ((((uint64)_pa) - KERNBASE) / PGSIZE)
#define MX_PGIDX PG2REFIDX(PHYSTOP)
#define PG_REFCNT(_pa) pg_refcnt[PG2REFIDX((_pa))]
int pg_refcnt[MX_PGIDX];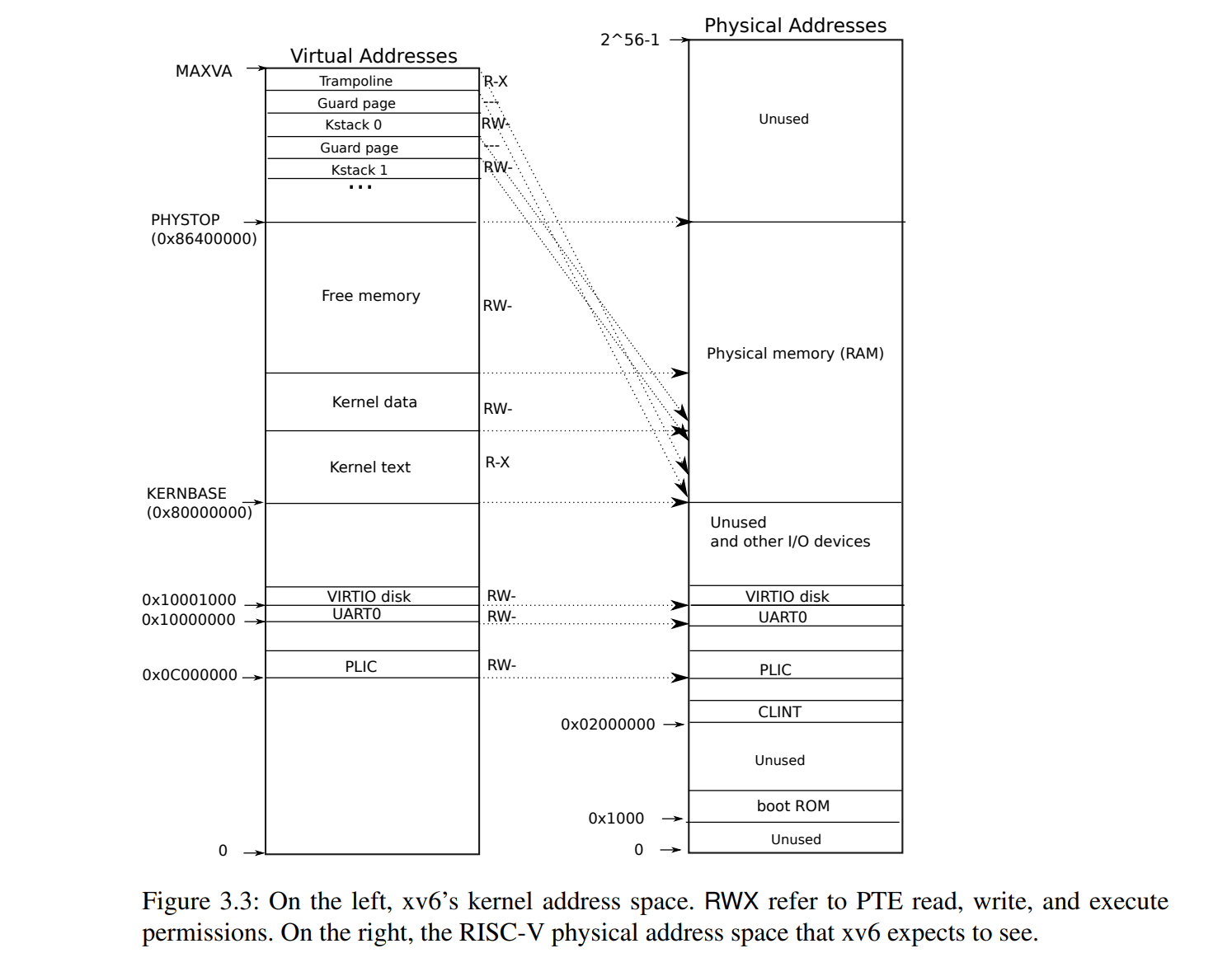
PHYSTOP 和 KERNBASE 代表着内存物理地址的起始和结束,所以我们要把 pa 减去 KERNBASE 后再除以 PGSIZE。
最大索引 MX_PGIDX 就是 PG2REFIDX(PHYSTOP),所以数组的大小要开 MX_PGIDX。
修改kernel/kalloc.c中的kalloc(),将页面的引用计数设置为 1。
void *kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r) kmem.freelist = r->next;
release(&kmem.lock);
if(r){
memset((char*)r, 5, PGSIZE); // fill with junk
PG_REFCNT(r) = 1;
}
return (void*)r;
}接下来是 kfree(), 只有在其引用计数为零时才应将页面放回空闲列表。
void kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
acquire(&refcnt.lock);
if(--PG_REFCNT(pa) <= 0){
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
release(&refcnt.lock);
}其中的 refcnt_lock 是一个锁,其初始化在 kinit() 中。
struct spinlock refcnt_lock;
void kinit()
{
initlock(&kmem.lock, "kmem");
initlock(&refcnt_lock, "refcnt");
freerange(end, (void*)PHYSTOP);
}这里加锁是因为可能有多个引用某个页的进程同时 kfree() 这个页,那么他们同时减少引用计数就会造成错误的结果。
然后在 kernel/vm.c 的 uvmcopy() 中,需要增加父进程页帧的引用计数(多一个进程在共享这个页帧)。
...
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
pte &= (~PTE_W);
pte |= PTE_C;
flags = PTE_FLAGS(*pte);
if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
goto err;
}
refcnt_inc(pa);
}
...在kernel/kalloc.c中编写refcnt_inc()方法:
void refcnt_inc(void *pa){
acquire(&refcnt_lock);
PG_REFCNT(pa)++;
release(&refcnt_lock);
}明明只有几行却要写个函数,因为我的
refcnt_lock定义在kalloc.c里。
Info
修改copyout()以在遇到 COW 页面时使用与页面错误相同的方案。
修改 copyout() 的原因主要是有些系统调用也会去往 COW 页上写数据。因为 COW 页的 PTE_W 没有设置,就会引发缺页错误。在 trap.c 中,我们规定了如果异常是从系统调用发生的,就会直接 panic。所以在 copyout() 的时候,如果我们发现了当前页是 COW 页,就直接给他分配一个新的页。
int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
if(uncopy_cow(pagetable, va0)){
try(cowalloc(pagetable, va0), return -1);
}
pa0 = walkaddr(pagetable, va0);
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}The End
好难!明明需要修改的地方提示都说了,我自己做还是做不出来。。。
对于这个系统的理解,以及对于编写大型C语言项目的能力都有待加强。