Appearance
networking
开启新实验
git fetch
git checkout net
make cleanBackground 机翻
您将使用名为 E1000 的网络设备来处理网络通信。对于 xv6(以及您编写的驱动程序),E1000 看起来像一个连接到真实以太网局域网 (LAN) 的真实硬件。事实上,您的驱动将与之交谈的 E1000 是 qemu 提供的模拟,连接到也由 qemu 模拟的 LAN。在此模拟 LAN 上,xv6(“来宾”)的 IP 地址为 10.0.2.15。Qemu 还安排运行 qemu 的计算机出现在 IP 地址为 10.0.2.2 的 LAN 上。当 xv6 使用 E1000 向 10.0.2.2 发送数据包时,qemu 会将数据包传送到运行 qemu 的(真实)计算机上的相应应用程序(“主机”)。
您将使用 QEMU 的“用户模式网络堆栈”。QEMU的文档在此处提供了有关用户模式堆栈的更多信息。我们更新了 Makefile 以启用 QEMU 的用户模式网络堆栈和 E1000 网卡。
Makefile 将 QEMU 配置为将所有传入和传出数据包记录到实验室目录中的 packets.pcap 文件中。查看这些记录以确认 xv6 正在传输和接收您期望的数据包可能会有所帮助。要显示录制的数据包:
tcpdump -XXnr packets.pcap我们已将一些文件添加到此实验室的 xv6 存储库中。文件 kernel/e1000.c 包含 E1000 的初始化代码以及用于发送和接收数据包的空函数,您将填写这些函数。kernel/e1000_dev.h 包含由 E1000 定义并在英特尔 E1000 Software Developer's Manual中描述的寄存器和标志位的定义。kernel/net.c 和 kernel/net.h 包含一个简单的网络堆栈,用于实现 IP、UDP 和 ARP 协议。这些文件还包含用于保存数据包的灵活数据结构的代码,称为 mbuf。最后,kernel/pci.c 包含在 xv6 启动时在 PCI 总线上搜索 E1000 卡的代码。
E1000 的交互方法
内容来自:MIT 6.s081 Xv6 Lab8 Networking 实验记录 | tzyt的博客
E1000 使用了 DMA(direct memory access)技术,可以直接把接收到的数据包写入计算机的内存,这在数据量大的时候非常有用,可以当作缓存。
在发送时也可以把描述符(见下文)写入内存的特定位置,这样 E1000 就会自己去找到待发送的数据,然后发送。
不管是接收还是发送,数据包都是以描述符数组描述的。在下面的接收和发送部分,会分别介绍接收描述符和发送描述符的格式。
接收
如果网卡收到了数据,会产生一个中断,然后调用对应的中断处理程序去处理这个新到达的数据。
描述符
接收描述符的格式如下:
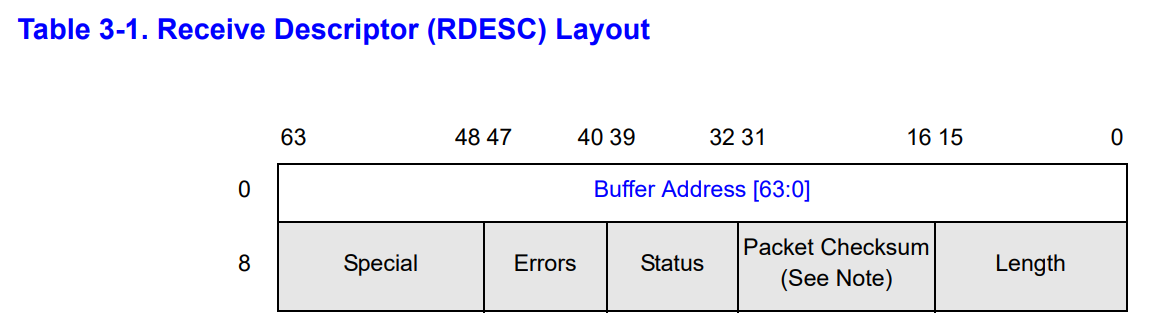
在 kernel/e1000_dev.h 中,这个描述符的定义如下:
// [E1000 3.2.3]
struct rx_desc
{
uint64 addr; /* Address of the descriptor's data buffer */
uint16 length; /* Length of data DMAed into data buffer */
uint16 csum; /* Packet checksum */
uint8 status; /* Descriptor status */
uint8 errors; /* Descriptor Errors */
uint16 special;
};我们会在内存中放一个数组的描述符,然后这个数组会被解读成一个环形队列。
如果网卡接收到了一个新的数据包,会检查环形队列 head 位置的描述符。然后把数据写入 head 描述符的缓冲区,也就是 addr 记录的地址。
这里比较重要的还有 status 和 length 属性。网卡在写入的时候就会设置这些属性。
其中,length 表示写入 addr 的数据包长度。status 则可以代表下列状态:

其中,我们需要用到的主要是 DD (Descriptor Done) 这个标志位。其表示网卡已经接收好了这个包。
在编写驱动的过程中,我们需要注意判断这个标志位,如果还没有完全接收好,我们就应该继续等待一段时间。
环形队列
上面我们提到了,如果网卡收到了新的数据,会往环形队列 head 位置描述符的缓冲区写入数据,下面来讨论网卡和驱动程序是如何具体管理这个缓冲区的。
下图展示了接收描述符环形队列的结构:
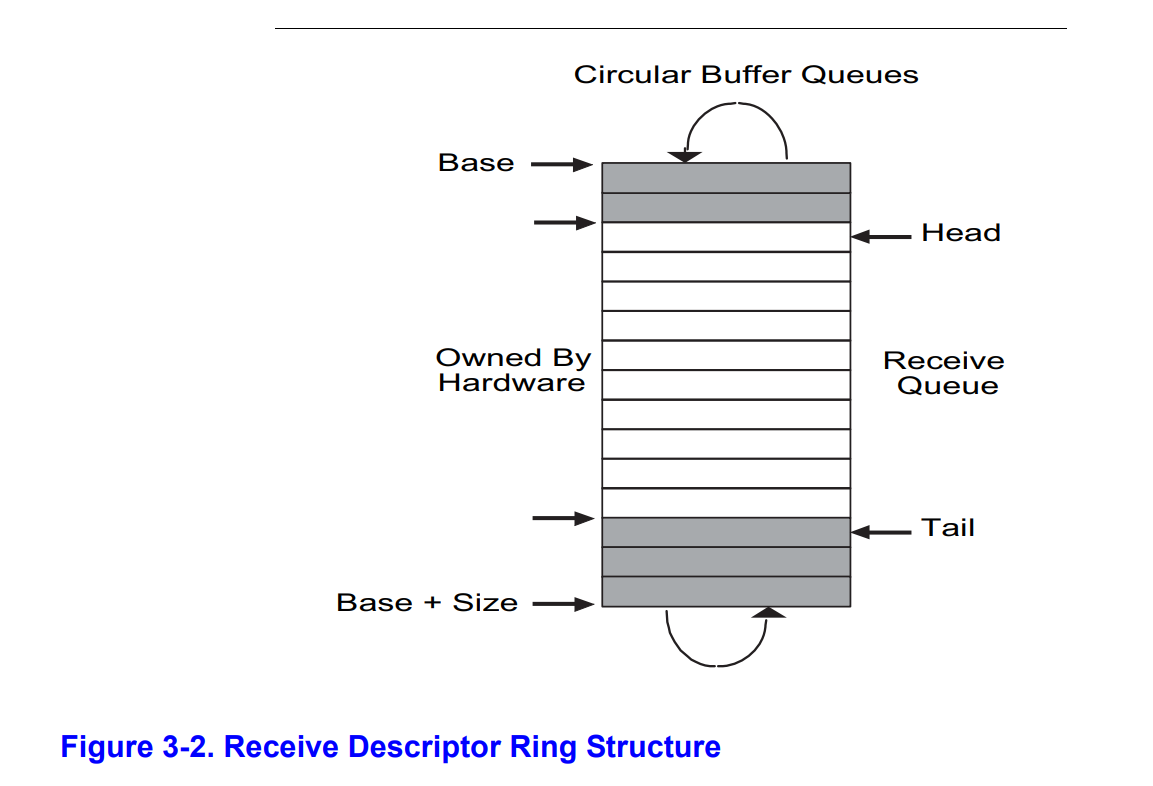
初始化时,head 为 0,tail 为队列缓冲区减一。
其中,head 到 tail 的这段浅色的区域是空闲的(图好像有点问题,其实 tail 指向的位置也时空闲的)。也就是说,这个区域内的数据包都已经被软件处理好了,那么如果有新的数据包到达,网卡会把数据写入这个区域的开始,也就是 head,把老的数据覆盖掉。网卡把老的数据覆盖掉后会把 head 的值加一。
而软件会按照顺序处理深色的区域。读取环形队列时,读取的是 tail + 1 位置描述符缓冲区的数据(这个位置是所有未处理数据中等待时间最长的),处理完这个缓冲区后会把 tail 增加一。
发送
描述符
发送描述符的格式如下:

在 kernel/e1000_dev.h 中,这个描述符的定义如下:
// [E1000 3.3.3]
struct tx_desc
{
uint64 addr;
uint16 length;
uint8 cso; // checksum offset
uint8 cmd; // command field
uint8 status; //
uint8 css; // checksum start field
uint16 special; //
};其中 addr 和 length 的作用和接收描述符的作用相同,这里不赘述。
除了这两个,我们主要还需要用到 cmd 和 status 这两个属性。
和接收标志位一样,在 status 中我们需要用到 DD 标志位,表示当前标志位指向的数据是否发送完成。
而 cmd 描述了传输这个数据包时的一些设置,或者说对于网卡的命令。
有以下的命令可以选择:

这里需要用到的命令有如下几个:
- RPS (Report Packet Sent):设置之后,网卡会报告数据包发送的状态。比如,在描述符指向的数据发送完成后,网卡会设置描述符的 DD 标志位。
- EOP (End of Packet):表明这个描述符是数据包的结尾。如果要发送的数据包特别大,我们可能会用很多个描述符的缓存空间来储存一个包。那么可以给这个数据包的最后一个描述符设置 EOP 命令。只有这样才能给这个描述符加上一些别的功能,如 IC,即加入和校验。
环形队列
和接收描述符的环形队列略有不同,发送描述符的 head 到 tail 这段区域(途中浅色区域)表示我们希望发送,但是网卡还没发送出去的数据。
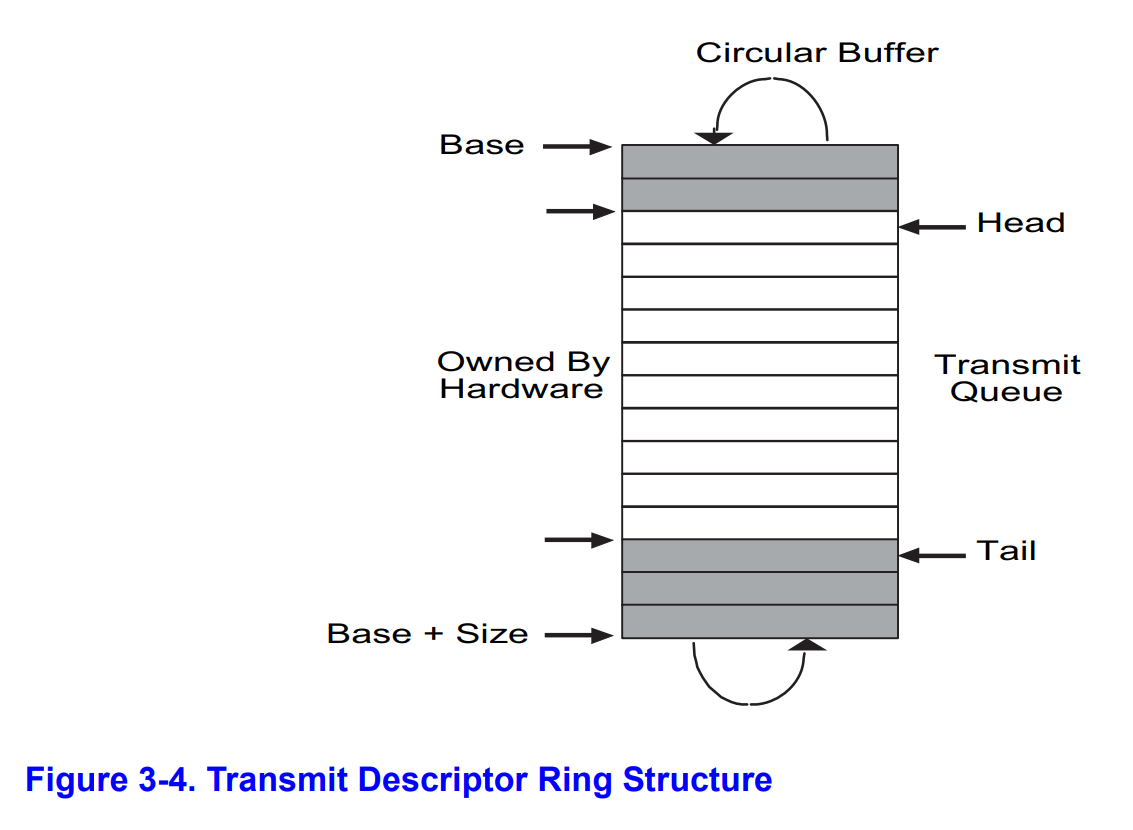
其中 head 指向等待时间最长的待发送数据,网卡会从这里开始发送。完成后会把 tail 加一而如果我们要新加入一个描述符,是从 tail 这个方向加入的,也会把 tail 加一。
xv6 对网络数据的描述
为了方便网络数据的处理,kernel/net.h 还定义了一个结构体,即 struct mbuf,如下:
struct mbuf {
struct mbuf *next; // the next mbuf in the chain
char *head; // the current start position of the buffer
unsigned int len; // the length of the buffer
char buf[MBUF_SIZE]; // the backing store
};在 e1000_transmit() 函数中,我们就需要接收一个 mbuf 类型的网络数据,然后写入 DMA 对应的内存地址,进而让网卡发送这个数据。
mbuf 的结构大致是下面这样的:
// The above functions manipulate the size and position of the buffer:
// <- push <- trim
// -> pull -> put
// [-headroom-][------buffer------][-tailroom-]
// |----------------MBUF_SIZE-----------------|
//
// These marcos automatically typecast and determine the size of header structs.
// In most situations you should use these instead of the raw ops above.
#define mbufpullhdr(mbuf, hdr) (typeof(hdr)*)mbufpull(mbuf, sizeof(hdr))
#define mbufpushhdr(mbuf, hdr) (typeof(hdr)*)mbufpush(mbuf, sizeof(hdr))
#define mbufputhdr(mbuf, hdr) (typeof(hdr)*)mbufput(mbuf, sizeof(hdr))
#define mbuftrimhdr(mbuf, hdr) (typeof(hdr)*)mbuftrim(mbuf, sizeof(hdr))----------------MBUF_SIZE-----------------|其中的 headroom 可以被 push 进去,用来储存网络协议的包头。在接收网络数据后也可以把中间 buffer 的部分 pull 进去来转换成如下的包头:
// an Ethernet packet header (start of the packet).
struct eth {
uint8 dhost[ETHADDR_LEN];
uint8 shost[ETHADDR_LEN];
uint16 type;
} __attribute__((packed));转换的部分可以在 net_rx() 函数找到:
struct eth *ethhdr;
uint16 type;
ethhdr = mbufpullhdr(m, *ethhdr);而 buffer 部分是数据正文,剩下的 tailroom 是 char buf[MBUF_SIZE] 这个缓存除去前两部分的剩下部分。
在 struct mbuf 结构体中,len 表示正文的长度,head 表示 headroom 的结束位置。
在 net.c 中有很多和 mbuf 相关的函数,最主要的就是 mbufalloc() 和 mbuffree() 分别对应着 mbuf 的分配和释放。
寄存器操作
我们可以通过特定的内存映射访问到 E1000 的控制寄存器。具体来说,是通过 e1000.c 中的 regs 全局变量加上一些偏移量。在 e1000_dev.h 中定义了额这些偏移量。
Your Job
这个实验的任务其实就是完成kernel/e1000.c中的e1000_transmit()和e1000_recv()。
发送:e1000_transmit()
根据提示:当 net.c 中的网络堆栈需要发送数据包时,它会使用包含要发送的数据包的 mbuf 调用 e1000_transmit()。传输代码必须在 TX(传输)环的描述符中放置指向数据包数据的指针。struct tx_desc 描述描述符格式。您需要确保每个 mbuf 最终都被释放,但只有在 E1000 完成数据包传输后才能释放(E1000 在描述符中设置E1000_TXD_STAT_DD位以指示这一点)。
- 首先通过
regs[E1000_TDT]得到当前环形队列的 tail(第一个没在发送的描述符位置),然后通过&tx_ring[idx]取得 tail 对应的描述符。 - 检测当前描述符的状态。如果没有
E1000_TXD_STAT_DD这个标志位,说明这一整个队列已经没有空闲的位置了(或者说这个 tail 已经碰到了环形队列的浅色区域了,也就是整个队列都储存了待发送的描述符)。在这种情况下,我们需要直接返回。 - 检测这个描述符对应的
mbuf的状态。描述符的addr属性会指向这个mbuf,如果这个描述符中的数据(也就是对应的mbuf)已经发送完了,那就可以把这个mbuf释放掉。 - 让描述符的
addr指向当前要发送的数据了。并且还需要更新数据长度。 - 在更新好描述符的
addr和len后,还需要设置对这个描述符的命令。
int e1000_transmit(struct mbuf *m)
{
acquire(&e1000_lock); // 可能多个线程同时发送,所以要加锁
uint idx = regs[E1000_TDT]; // transmit tail,表明第一个空闲的环形描述符
struct tx_desc *desc = &tx_ring[idx];
if(!(desc->status & E1000_TXD_STAT_DD)){ // 是否传输完成,没传完的话说明环形缓冲区没了,是错误
release(&e1000_lock);
return -1;
}
if(tx_mbufs[idx] != NULL){ // 这里的 buf 指向要发的数据包
// 因为前面的判断,这里肯定是发送完了
// tx_mbufs 是不需要分配的,直接指向 m 这个参数
mbuffree(tx_mbufs[idx]);
tx_mbufs[idx] = NULL;
}
desc->addr = (uint64)m->head;
desc->length = m->len;
desc->cmd = E1000_TXD_CMD_RS | E1000_TXD_CMD_EOP;
tx_mbufs[idx] = m; // 方便之后清理
regs[E1000_TDT] = (idx + 1) % TX_RING_SIZE; // 更新 tail 的位置
release(&e1000_lock);
return 0;
}接收:e1000_recv()
根据提示:当 E1000 从以太网接收每个数据包时,它首先将数据包 DMA 到下一个 RX(接收)环描述符指向的 mbuf,然后生成中断。您的 e1000_recv() 代码必须扫描 RX 环,并通过调用 net_rx() 将每个新数据包的 mbuf 传送到网络堆栈(在 net.c 中)。然后,您需要分配一个新的 mbuf 并将其放入描述符中,以便当 E1000 再次到达 RX 环中的该点时,它会找到一个新的缓冲区,将新数据包 DMA 到该缓冲区中。
- 在
e1000_recv()中,我们需要一次性读出所有的待读取数据包。也就是需要加一个循环,然后一直读取tail位置的描述符,直到描述符的状态为未完成接收。 - 先读取 tail 的位置,然后取得对应的描述符
- 判断是否读完了所有待读取的描述符
- 重新设置
mbuf的长度 - 随后需要调用
net_rx()函数把这个mbuf转发到相应的网络协议栈进行处理 - 因为上层的协议栈还需要使用这个
mbuf,所以我们不能将其覆盖,需要给当前描述符分配一个新的mbuf - 最后一步是更新 tail 指向的位置(注意 tail 本身是已经被软件处理过的描述符)
static void
e1000_recv(void)
{
while(1){
uint idx = (regs[E1000_RDT] + 1) % RX_RING_SIZE;
struct rx_desc *desc = &rx_ring[idx];
if(!(desc->status & E1000_RXD_STAT_DD)){
return;
}
rx_mbufs[idx]->len = desc->length;
net_rx(rx_mbufs[idx]);
rx_mbufs[idx] = mbufalloc(0);
desc->addr = (uint64)rx_mbufs[idx]->head;
desc->status = 0;
regs[E1000_RDT] = idx;
}
}The End
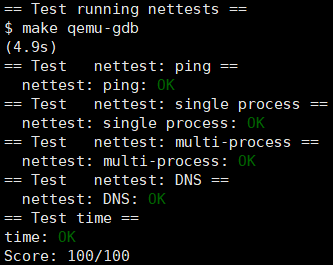
好好看文档和源码。