Appearance
locks
开启新实验
git fetch
git checkout lock
make cleanMemory allocator
任务描述
在原本的 kalloc() 中,只维护 freelist 链表,如果有任何程序申请内存,都需要竞争 freelist 的锁,以修改 freelist 的内容。具体可见 freelist 和 kalloc() 的实现:
// kernel/kalloc.c
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
...
// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}可以发现,不可能同时有多个核心去调用 kalloc() 函数以及 kfree() 函数,大大降低了内存分配的效率。
按照题目的描述进行测试,可以发现这个锁就是一个很大瓶颈(kmem 这个锁是所有锁中等待次数最多,竞争最激烈的):
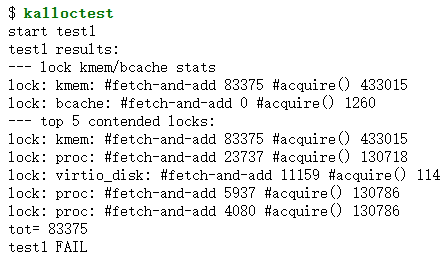
在这个 lab 中需要解决这个问题。实验提示中给出的提示是给每个处理器核心都分配一个 freelist。
实现过程
因为题目要求必须以“kmem”开头命名锁名称,这涉及到字符串格式化,所以根据提示需要了解
snprintf()函数的用法。查看
kernel/sprintf.c得出,可以这样使用:snprintf(kmem_lk_n[i], name_sz, "kmem cpu %d", i);在初始化的时候,应该对每一个cpu初始化锁。
struct { struct spinlock lock; struct run *freelist; } kmems[NCPU]; const uint name_sz = sizeof("kmem cpu 0"); void kinit() { char name[sizeof("kmem cpu 0")]; for(int i=0; i<NCPU; i++){ snprintf(name, name_sz, "kmem cpu %d", i); initlock(&kmems[i].lock, name); } freerange(end, (void*)PHYSTOP); }而最后各个cpu释放空间时应该释放自己的空间。根据提示,函数
cpuid()返回当前的核心编号,但只有在中断关闭时调用它并使用其结果才是安全的,应该使用push_off()和pop_off()来关闭和打开中断。// Free the page of physical memory pointed at by v, // which normally should have been returned by a // call to kalloc(). (The exception is when // initializing the allocator; see kinit above.) void kfree(void *pa) { struct run *r; if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP) panic("kfree"); push_off(); uint cpu = cpuid(); pop_off(); // Fill with junk to catch dangling refs. memset(pa, 1, PGSIZE); r = (struct run*)pa; acquire(&kmems[cpu].lock); r->next = kmems[cpu].freelist; kmems[cpu].freelist = r; release(&kmems[cpu].lock); }根据题目,本任务的主要挑战是处理一个 CPU 的空闲列表为空,但另一个 CPU 的列表有空内存的情况。在这种情况下,一个 CPU 必须“窃取”另一个 CPU 的空闲列表的一部分。偷窃可能会引入锁争用,但希望这种情况不会经常发生。
可以直接修改
kalloc.c,首先是要获取当前 CPU 的编号,然后如果没有空闲的页帧了,扫描所有 CPU 的freelist,如果有空闲的就偷来加到当前 CPUfreelist中。// Allocate one 4096-byte page of physical memory. // Returns a pointer that the kernel can use. // Returns 0 if the memory cannot be allocated. void *kalloc(void) { struct run *r; push_off(); uint cpu = cpuid(); acquire(&kmems[cpu].lock); r = kmems[cpu].freelist; if(r){ kmems[cpu].freelist = r->next; } else { // 没有空闲页帧 release(&kmems[cpu].lock); struct run *ret=0; // 扫描所有 CPU 的 freelist for(int i = 0; i < NCPU; i++){ if(i == cpu) continue; acquire(&kmems[i].lock); if(kmems[i].freelist){ // 找到空闲页帧 ret = kmems[i].freelist; kmems[i].freelist = kmems[i].freelist->next; release(&kmems[i].lock); break; } release(&kmems[i].lock); } if(ret == 0){ // 无空闲页帧则退出 pop_off(); return 0; } acquire(&kmems[cpu].lock); ret->next = kmems[cpu].freelist; // 加到当前 CPU 的 freelist 前 r = ret; } release(&kmems[cpu].lock); if(r) memset((char*)r, 5, PGSIZE); // fill with junk pop_off(); return (void*)r; }
Buffer cache
任务描述
在 xv6 中不能直接访问硬盘设备的,如果想要读取硬盘中的数据,需要先把数据拷贝到一个缓存中,然后读取缓存中的内容。
这个实验就是要对 xv6 的磁盘缓冲区进行优化。在初始的 xv6 磁盘缓冲区中是使用一个如下图所示的LRU双向链表来维护,而这就导致了每次获取、释放缓冲区时就要对整个链表加锁,也就是说缓冲区的操作是完全串行进行的。
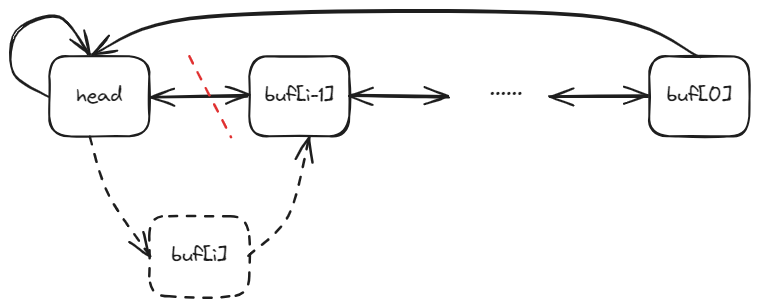
实验描述中给的提示是实现一个哈希表。哈希表会把块号映射到块缓存的桶,那么只有两个进程试图操作同一个桶中的块缓存,才会造成竞争。而且在查找所需块缓存时只需要在对应的桶中查找。
当然,在对应桶中没有足够缓存时,可以像在 kalloc() 中一样,从别的桶中偷缓存。
实现过程
修改
buf的结构。原本只有一个双向链表是可以实现 LRU 的,但是分为多个桶后有多个链,只能保证是桶中的 LRU 而不是全局的。在buf中添加一个成员timestamp通过全局变量ticks记录最后使用的时间,需要进行替换时找timestamp最小(离目前时间最久)的块。// kernel/buf.h struct buf { ... uint timestamp; }准备工作:定义结构体等。
// kernel/bio.c #define NBUK 13 #define hash(dev, blockno) ((dev * blockno) % NBUK) struct bucket{ struct spinlock lock; struct buf head; } buckets[NBUK]; struct { struct spinlock lock; struct buf buf[NBUF]; } bcache;根据题目的提示,桶的数量定为13,哈希函数随便写的(应该问题都不大吧)。
binit():需要完成锁以及链表的初始化。我选择初始时将所有的块的放到0桶,也可以按其他方式分配,分配后可以避免后续写代码时还要判断空指针。void binit(void) { struct buf *b; initlock(&bcache.lock, "bcache"); for(int i = 0; i < NBUK; i++){ initlock(&buckets[i].lock, "bcache.bucket"); buckets[i].head.prev = &buckets[i].head; buckets[i].head.next = &buckets[i].head; } for(b = bcache.buf; b < bcache.buf+NBUF; b++){ b->timestamp = ticks; initsleeplock(&b->lock, "buffer"); b->prev = &buckets[0].head; b->next = buckets[0].head.next; buckets[0].head.next->prev = b; buckets[0].head.next = b; } }我还是维护双向链表,有些人会写成单链表这样经常还要记录前一个指针,代码写起来比较容易出错。个人感觉双向链表删除结点很方便而且可读性也比较好。
bget():该任务的难点。这个函数主要是先看是否已经缓存,如果没有缓存就要去找最久没使用的块。先实现第一部分简单的,基本按照原代码,换成桶级的就可以。static struct buf* bget(uint dev, uint blockno) { struct buf *b; int buk_id = hash(dev, blockno); // Is the block already cached? acquire(&buckets[buk_id].lock); for(b = buckets[buk_id].head.next; b != &buckets[buk_id].head; b = b->next){ if(b->dev == dev && b->blockno == blockno){ b->refcnt++; release(&buckets[buk_id].lock); acquiresleep(&b->lock); return b; } } release(&buckets[buk_id].lock); ... }最后为什么要释放锁呢?如果不释放会出现下面的情况:
假设块号 b1 的哈希值是 2,块号 b2 的哈希值是 5 并且两个块在运行前都没有被缓存 ---------------------------------------- CPU1 CPU2 ---------------------------------------- bget(dev, b1) bget(dev,b2) | | V V 获取桶 2 的锁 获取桶 5 的锁 | | V V 缓存不存在,遍历所有桶 缓存不存在,遍历所有桶 | | V V ...... 遍历到桶 2 | 尝试获取桶 2 的锁 | | V V 遍历到桶 5 桶 2 的锁由 CPU1 持有,等待释放 尝试获取桶 5 的锁 | V 桶 5 的锁由 CPU2 持有,等待释放 !此时 CPU1 等待 CPU2,而 CPU2 在等待 CPU1,陷入死锁!bget():第二部分,尚未缓存,在所有的块里找到最久未使用的然后进行替换。看似简单,但是锁来锁去好乱。for bucket in buckets: 获取当前桶的锁; 遍历桶找更合适的块; if 该桶有更合适的块: 释放原来合适的块所在桶的锁; else: 释放当前桶的锁;就是说找到更合适的块后,要保留它所在桶的锁,不然可能会被其他进程所修改。
将这个合适的块从原来的桶中取出然后释放原来的桶的锁。再获取目标桶的锁,将这个块插入到目标桶的链表中。
static struct buf* bget(uint dev, uint blockno) { ... int min_timestamp = 0x3f3f3f3f; int lru_buk_id = -1; int is_better = 0; struct buf *lru_b = (void*)0; for(int i = 0; i < NBUK; i++){ acquire(&buckets[i].lock); for(b = buckets[i].head.next; b != &buckets[i].head; b = b->next){ if(b->refcnt == 0 && b->timestamp < min_timestamp){ min_timestamp = b->timestamp; is_better = 1; lru_b = b; } } if(is_better){ if(lru_buk_id != -1) release(&buckets[lru_buk_id].lock); lru_buk_id = i; } else { release(&buckets[i].lock); } is_better = 0; } // remove if(lru_b){ lru_b->prev->next = lru_b->next; lru_b->next->prev = lru_b->prev; release(&buckets[lru_buk_id].lock); } // insert acquire(&bcache.lock); acquire(&buckets[buk_id].lock); if(lru_b){ lru_b->prev = &buckets[buk_id].head; lru_b->next = buckets[buk_id].head.next; buckets[buk_id].head.next->prev = lru_b; buckets[buk_id].head.next = lru_b; } ... }bget():还有重点,因为之前将目标桶的锁释放了,现在重新获取, 我们需要的块有可能已经被其他进程缓存了,所以要先在目标桶里再找一遍,没有的话再修改我们刚插入的块的数据,否则会导致重复缓存。static struct buf* bget(uint dev, uint blockno) { ... for(b = buckets[buk_id].head.next; b != &buckets[buk_id].head; b = b->next){ if(b->dev == dev && b->blockno == blockno){ b->refcnt++; release(&buckets[buk_id].lock); release(&bcache.lock); acquiresleep(&b->lock); return b; } } // not find lru_b when travel each bucket if (lru_b == 0) panic("bget: no buffers"); lru_b->dev = dev; lru_b->blockno = blockno; lru_b->valid = 0; lru_b->refcnt = 1; release(&buckets[buk_id].lock); release(&bcache.lock); acquiresleep(&lru_b->lock); return lru_b; }brelse():修改为桶级锁,不需要维护块的位置了,但要维护timestamp。void brelse(struct buf *b) { if(!holdingsleep(&b->lock)) panic("brelse"); releasesleep(&b->lock); int buk_id = hash(b->dev, b->blockno); acquire(&buckets[buk_id].lock); b->refcnt--; // update timestamp when it is a free buf (b->refcnt == 0) if(b->refcnt == 0) b->timestamp = ticks; release(&buckets[buk_id].lock); }最后将
bpin和bunpin的锁替换为桶级锁就行了。void bpin(struct buf *b) { int buk_id = hash(b->dev, b->blockno); acquire(&buckets[buk_id].lock); b->refcnt++; release(&buckets[buk_id].lock); } void bunpin(struct buf *b) { int buk_id = hash(b->dev, b->blockno); acquire(&buckets[buk_id].lock); b->refcnt--; release(&buckets[buk_id].lock); }
The End
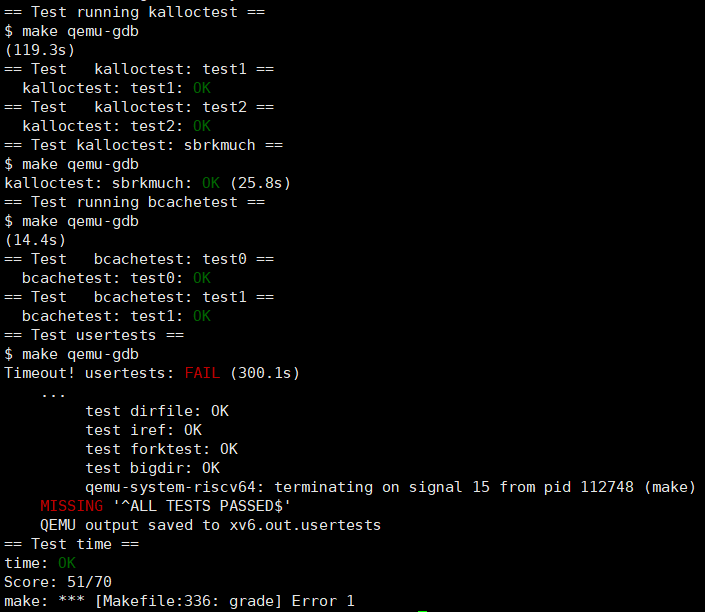
第二个实验看了好多人的博客,按照自己的思路写了一遍又一遍,但是还是总是会出现各种问题(应该是因为我的锁的使用有点问题),panic又很莫名其妙,还有的是在usertests的某个测试里卡住了(我估摸着说不定是死锁)。
usertests 其实都PASS了但是超时了,应该也不是代码问题因为用别人AC的代码也过不了,说不定是我租的便宜服务器性能太差了。