Appearance
Advanced CNN
前面的网络结构都是串行的,但实际上网络可以具有更复杂的结构。
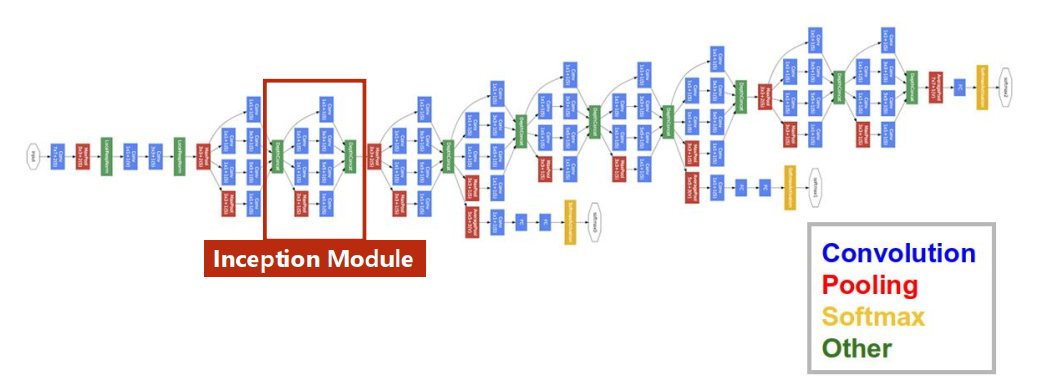
GooLeNet
减少代码的冗余:函数/类
可以发现网络中有许多结构相同的模块(Inception Module),可以将其封装成类。
Inception Module
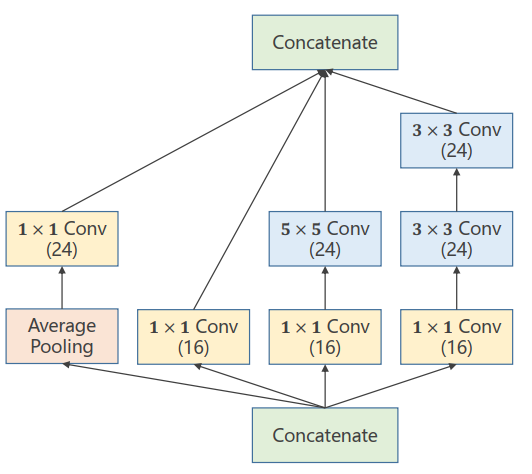
一个典型的Inception Module的例子:
为什么要采用并行的结构?
- 构造神经网络时超参数难以选择,于是采用并行以尝试多种卷积组合
- 效果好的卷积组合权重变大,最终可以找到最优的卷积组合
Concatenate:张量拼接
为了不同卷积组合的结果能够拼接,中除了都必须相同。
可以使用padding和stride调整结果。
What is 1x1 convolution?
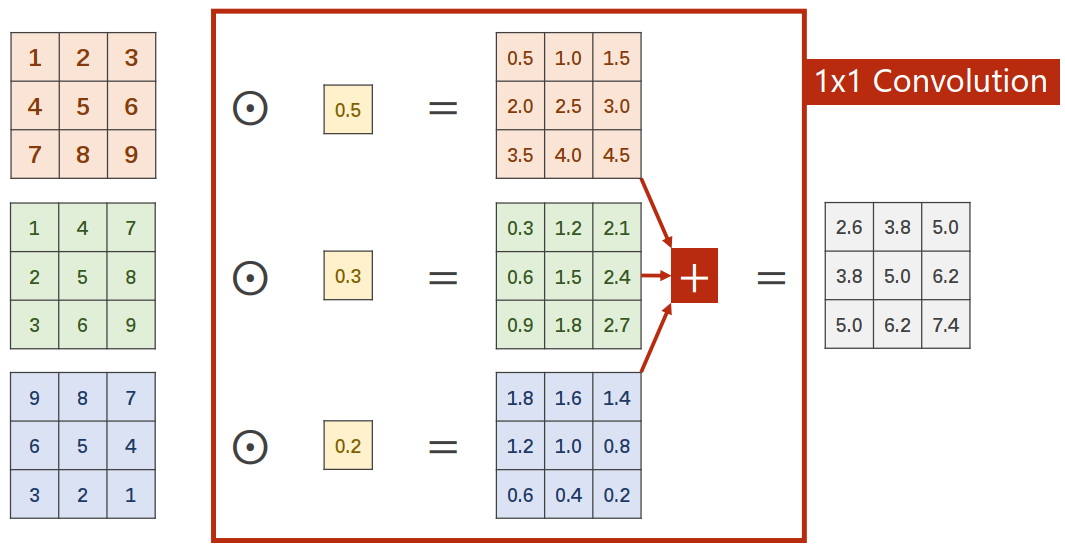
可以看出,的卷积不会使信息丢失,输入的三个张量发生了信息融合。
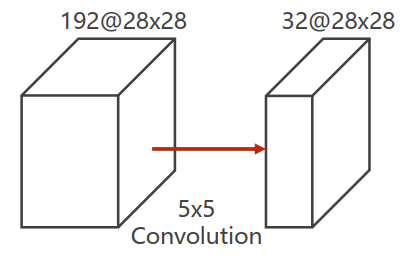
- 卷积核的大小是
- 假设对输入张量进行了padding,那么每个通道中取个块与卷积核卷积
- 输入张量有192个通道
- 输出张量要求通道数为32,所以输入张量分别与卷积核的32个通道进行卷积
所以最终需要的计算次数为:
运算量太大!!!
的卷积可以改变通道数量以降低运算量。
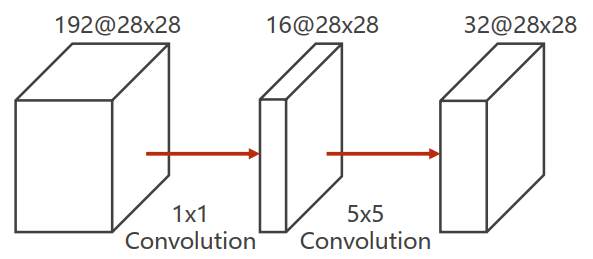
所需计算次数为:
运算量只有之前的。
Implementation of Inception Module
分析各个分支
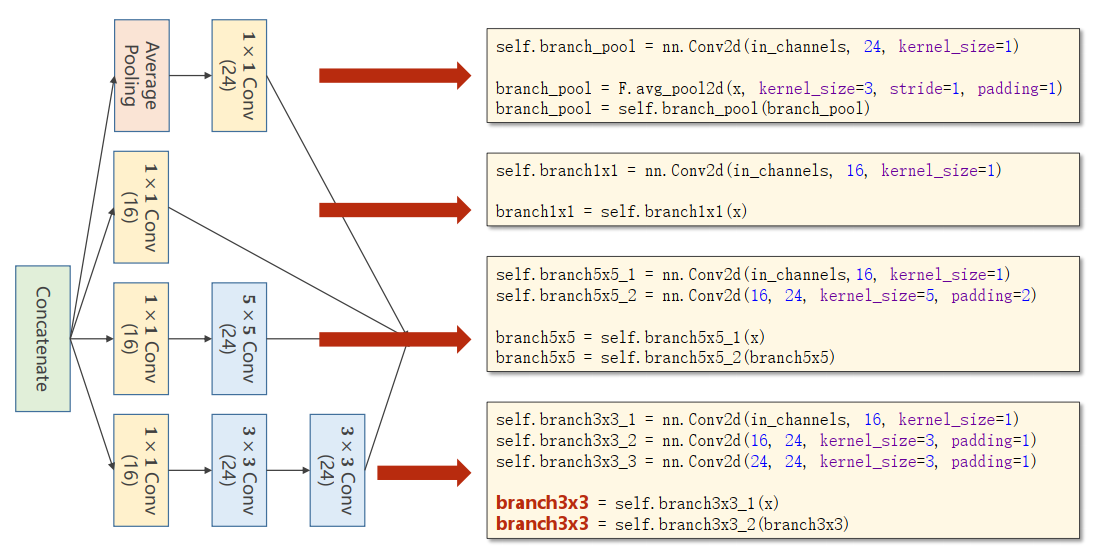
图片最后漏了
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)拼接
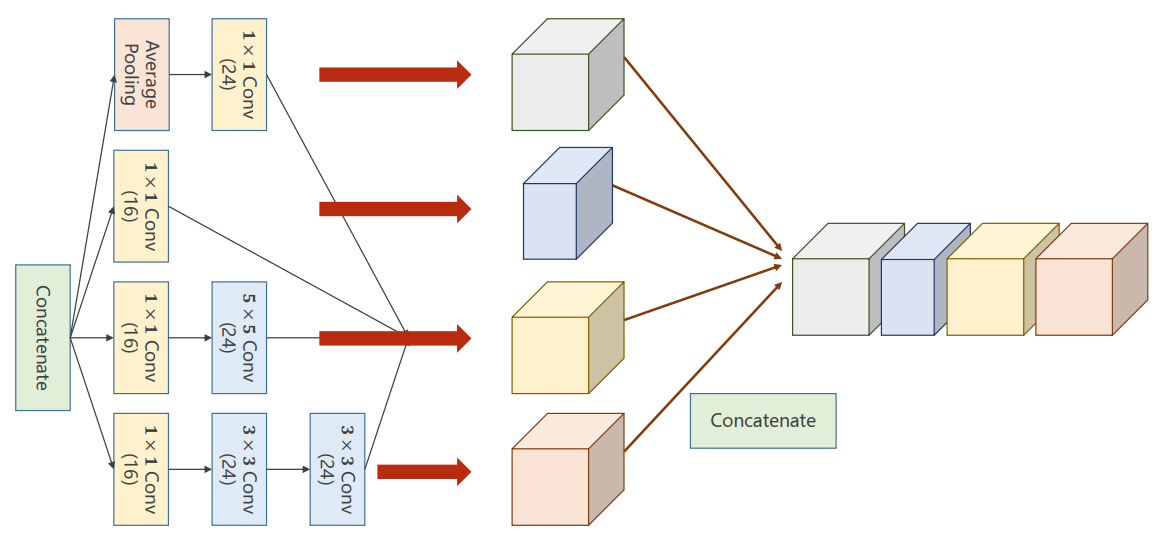
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1)代码实现
class InceptionA(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1)Using Inception Module
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0) # 1*28*28
x = F.relu(self.mp(self.conv1(x))) # 卷积10*24*24、池化10*12*12、relu
x = self.incep1(x) # 88*12*12
x = F.relu(self.mp(self.conv2(x))) # 卷积20*8*8、池化20*4*4、relu
x = self.incep2(x) # 88*4*4
x = x.view(in_size, -1) # 向量 88*4*4=1408
x = self.fc(x) # 全连接 1408->10
return x这个1408实际写代码不用自己算,看报错信息哈哈哈。
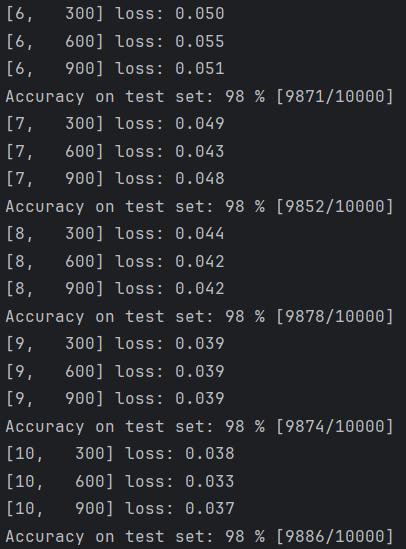
给之前MNIST的代码换上新模型,运行结果如下:
Can we stack layers to go deeper?
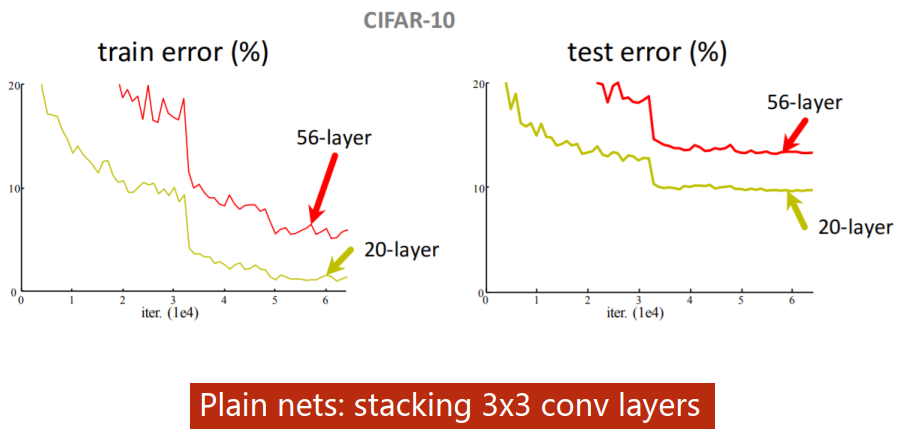
更多的层数叠加不一定能获得更好的效果。
- 过拟合
- 残差消失
- ...
Residual Network
Residual Net
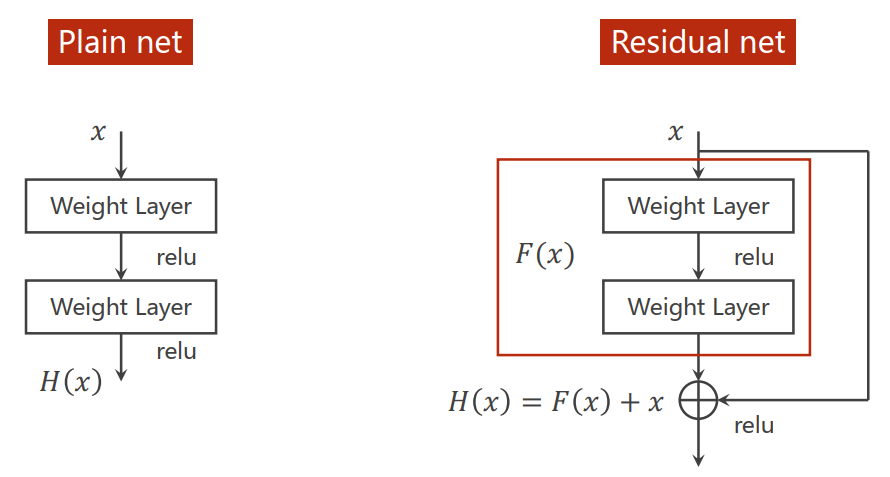
Residual Net进行的操作:输入张量经过卷积、激活、卷积后的结果加上原本的输入张量再进行激活。
Residual Net通过把原本可能很小的梯度变成1附近的数字解决梯度消失的问题:
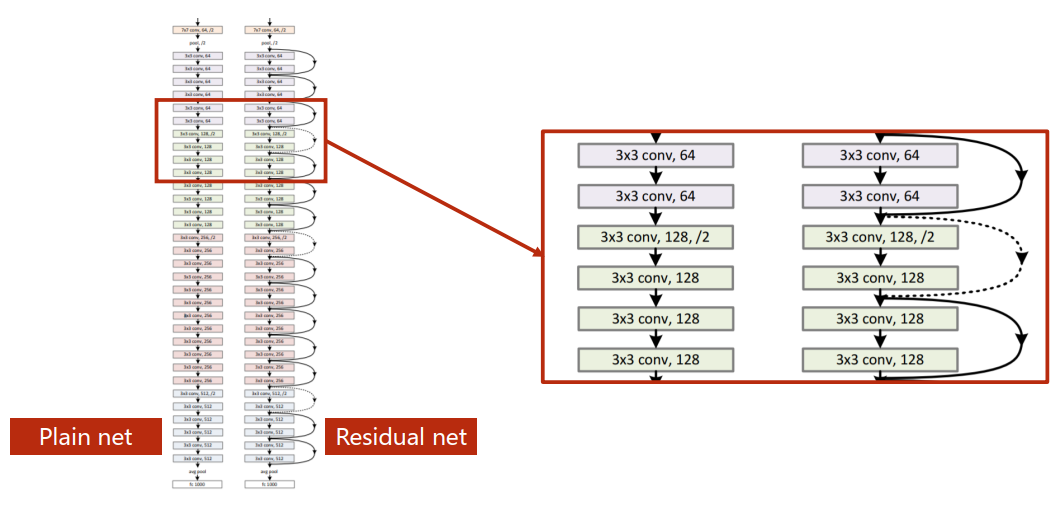
Residual net里存在跳连接,虚线是因为张量维度不同需要单独处理,可以直接不进行跳连接,也可以将x直接进行池化操作转化为同样的大小。
Implementation of Simple Residual Network

注意到Residual Block的输入和输出通道保持一致,可以传入通道数以确定输出的通道。
class ResidualBlock(nn.Module):
def __init__(self, channels):
super().__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x+y)网络的实现如下:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0) # 1*28*28
x = self.mp(F.relu(self.conv1(x))) # 卷积16*24*24,激活,池化16*12*12
x = self.rblock1(x) # Residual 16*12*12
x = self.mp(F.relu(self.conv2(x))) # 卷积32*8*8,激活,池化32*4*4
x = self.rblock2(x) # Residual 32*4*4=512
x = x.view(in_size, -1)
x = self.fc(x) # 全连接512->10
return x运行结果如下:
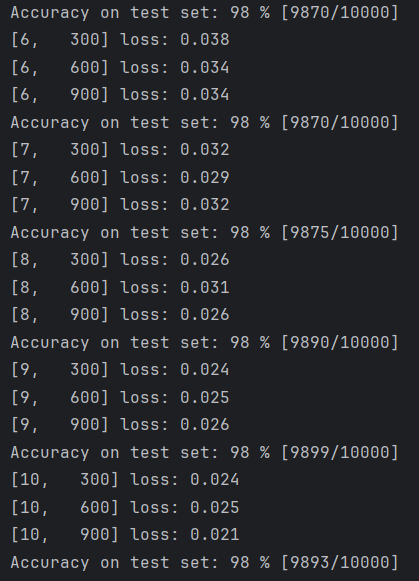
Tips
- 有多个分支,可以定义变量然后拼接不同分支运行结果。
- 可以用类封装结构相同的网络。
- 要计算好size,逐步扩大网络逐步测试。