Appearance
Linear Regression with PyTorch
用PyTorch提供的工具更方便地实现之前的线性模型。
- Prepare Dataset
- Design model using Class(计算)
- inherit from nn.Module
- Construct loss and optimizer
- using PyTorch API
- Training Cycle
- forward, backward, update
1. Prepare Dataset
In PyTorch, the computational graph is in mini-batch fashion, so X and Y are Tensors.
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])2. Design Model
不需要再自行推导梯度的公式,只需要把计算图构造好。
Affine Model:
Loss Function:
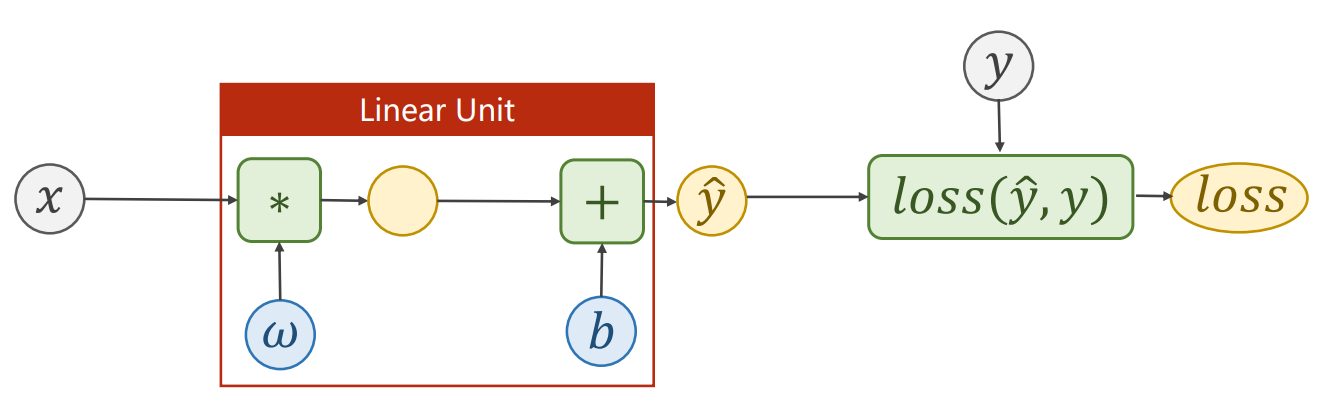
需要确定和的维度,根据进行判断。
得到的loss是一个标量。
class LinearModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()Our model class should be inherit from nn.Module, which is Base class for all neural network modules.
Member methods __init__() and forward() have to be implemented.
nn.Linear
Class nn.Linear contain 2 member Tensors: weight and bias.

接受三个参数输入维度(in_features)、输出维度(out_features)和可选的偏置(bias),进行的操作。
Note
行样本,列维度。
Class nn.Linear has implemented the magic method call(), which enable the instance of the class can be called just like a function. Normally the forward() will be called.
3. Construct Loss and Optimizer
criterion = torch.nn.MSELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)nn.MSELoss

- size_average: 是否求均值,一般False,mini-batch大小不同可以考虑一下True
- reduce: 是否降维
nn.optim.SDG

- params: 要优化的参数。这里params是
model.parameters(),model里是Linear,Linear有两个成员weight和bias。.parameters()能够递归地找到所有需要优化的参数。 - lr: 学习率。可以在不同部分使用不同的学习率。
Different Optimizer in Linear Regression
- torch.optim.Adagrad
- torch.optim.Adam
- torch.optim.Adamax
- torch.optim.ASGD
- torch.optim.LBFGS
- torch.optim.RMSprop
- torch.optim.Rprop
- torch.optim.SGD
4. Training Cycle
for epoch in range(100):
y_pred = model(x_data) # Forward: Predict
loss = criterion(y_pred, y_data) # Forward: Loss
print(epoch, loss)
optimizer.zero_grad() # before backward: set the grad to ZERO
loss.backward() # Backward: Autograd
optimizer.step() # Update完整代码
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
y_pred = model(x_data) # Forward: Predict
loss = criterion(y_pred, y_data) # Forward: Loss
print(epoch, loss.item())
optimizer.zero_grad() # before backward: set the grad to ZERO
loss.backward() # Backward: Autograd
optimizer.step() # Update
# Output weight and bias
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
# Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)