Appearance
Dataset and DataLoader
- Dataset支持通过索引获得数据
- DataLoader获取一个Mini-Batch
Terminology: Epoch, Batch-Size, Iterations
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):- Epoch: One forward pass and one backward pass of all the training examples.(训练周期数)
- Batch-Size: The number of training examples in one forward backward pass.(一个包里面有多少样本)
- Iteration: Number of passes, each pass using [batch size] number of examples.(一个训练周期里训练完所有包的迭代次数)
假设有10000个样本,Batch-Size为1000,那么Iteration就是10。
DataLoader: batch_size=2, shuffle=True
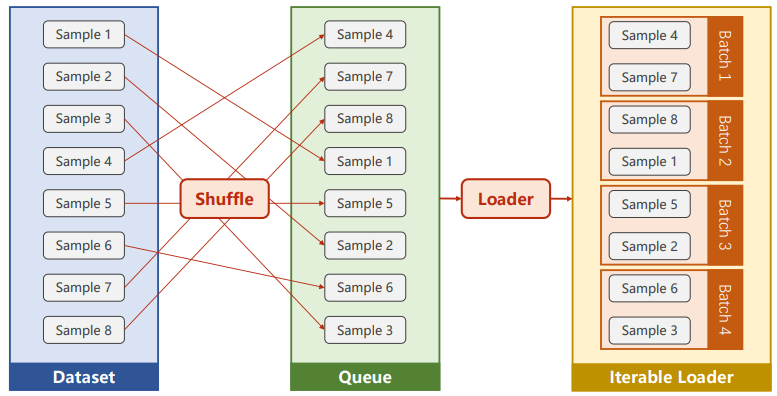
DataLoader需要Dataset可索引长度已知。
shuffle打乱数据,每个epoch不同。
打乱、分组、迭代
How to define your Dataset
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset): # 继承
def __init__(self): # 初始化
pass
def __getitem__(self, index): # 支持通过索引取出数据
pass
def __len__(self): # 返回dataset的长度
pass
dataset = DiabetesDataset()
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2) # 实例化DataLoader- Dataset是一个抽象类,只可继承不能实例化。实现自己的dataset后可以实例化
- DataLoader是一个类,可以实例化一个DataLoader进行数据处理
- 小数据集(结构化数据)可以直接在初始化时全部读入内存,大数据集(图像、语音等无结构数据)可以在初始化时建立一个列表存放文件名
Warning
num_workers in Windows
在Windows系统中创建一个进程用的是spawn,而Linux系统中用的是fork,所以会产生一些错误。
需要将训练的代码放在if语句中:

Example: Diabetes Dataset
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
# 数据准备
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
# 定义模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
def forward(self, x):
x = torch.sigmoid(self.linear1(x))
x = torch.sigmoid(self.linear2(x))
x = torch.sigmoid(self.linear3(x))
return x
model = Model()
# 构造损失和优化器
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练周期
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# prepare data
inputs, labels = data
# forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# backward
optimizer.zero_grad()
loss.backward()
# update
optimizer.step()torchvision.datasets
- MNIST
- Fashion-MNIST
- EMNIST
- COCO
- LSUN
- ImageFolder
- DatasetFolder
- Imagenet-12
- CIFAR
- STL10
- PhotoTour
这些dataset都是torch.utils.data.Dataset的子类,都具有__getitem__和__len__方法,可以用torch.utils.data.DataLoader进行加载,也可以使用多进程进行加速。
如何使用,以MNIST数据集的处理为例:
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
train_dataset = datasets.MNIST(root='../dataset/mnist',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
transform=transforms.ToTensor(),
download=True)
train_loader = DataLoader(dataset=train_dataset,
batch_size=32,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=32,
shuffle=False)
for batch_idx, (inputs, target) in enumerate(train_loader):
...