Appearance
MIT 6.S081 完结!
Lab Utilities
这个实验是在实现一些应用程序,基本都是在 user 文件夹下编写代码。这些应用程序涉及各个方面,让我对于用户指令以及一些基本概念有了更深刻的认识。
还知道了一个重要的文件 Makefile,它关系到了整个工程的编译规则。这个课程不怎么涉及 Makefile 的编写,只有在新增了文件的时候需要将这个文件添加到 Makefile 中去(或者有这个文件但是实验要我们自己去添加),否则就不会对该文件进行编译。
sleep
了解了一个用户程序的框架,并学会了如何处理命令行输入,如何查看源码以利用工具函数和系统调用来实现目标功能。
int main(int argc, char *argv[]),argc是参数个数,argv是输入的命令按空格划分后的字符串数组
pingpong
深入理解了父子进程间如何通过管道进行数据传递和同步。
int fork(),让一个进程生成另外一个和这个进程的内存内容相同的子进程,父进程返回子进程的PID,子进程返回0int pipe(int p[]),p[0]为读取的文件描述符,p[1]为写入的文件描述符- 每个进程各自有不同的用户地址空间,所以进程之间要交换数据必须通过内核
- 管道能够实现父子进程间的通信,是一种半双工通信(可以选择方向的单向通信)
primes
管道与多进程协作的复杂场景下的程序设计。
find
了解到了文件在操作系统中是什么样的形式,以及几个与文件有关的函数。
int open(const char *pathname, int flags),以什么样的形式打开目标路径下的文件int fstat(int filedes, struct *buf),获取文件描述符filedes所指向的文件的状态,可以知道这个文件的类型int read(int fd, char *bf, int n),从文件描述符fd读 n 字节的内容。如果fd是一个打开的目录的文件描述符,调用read函数将从该目录中读取目录项(dirent)
xargs
熟悉了复杂字符串处理和命令行解析的过程,并进一步掌握了进程管理和子进程控制。
- 将标准输入作为参数一起输入到xargs后面跟的命令中,如果标准输入有多行那就需要执行多次命令
- 用
read命令读标准输入。每个进程都拥有自己独立的文件描述符列表,其中0是标准输入,1是标准输出,2是标准错误 - fork一个子进程exec这个命令,父进程wait子进程
Lab System calls
xv6是一个宏内核,整个操作系统都在内核中,所有内核服务运行在一个地址空间中通信简单高效。
微内核只包含用户进程相关的服务,执行效率相对较慢(跨模块调用),但模块化之后很容易扩展,并且因为内核空间与用户空间相互隔离,在用户态下应用程序崩溃后一般不会影响到内核中的数据。
这个Lab主要是要了解系统调用的流程。
以Lab2的第一个实验为例:
user/user.h:注册trace使得用户态程序可以找到这个跳板入口函数user/usys.S:跳板函数trace()使用 CPU 提供的 ecall 指令,调用到内核态- 由
user/usys.pl脚本生成的汇编文件
- 由
kernel/syscall.c:到达内核态统一系统调用处理函数syscall(),所有系统调用都会跳到这里来处理kernel/syscall.c:syscall()根据跳板传进来的系统调用编号,查询syscalls[]表,找到对应的内核函数并调用- 系统调用编号在
kernel/syscall.h中定义 - 在
kernel/syscall.c中需要用extern全局声明新的内核调用函数,并且在syscalls[]表中,加入从前面定义的编号到系统调用函数指针的映射
- 系统调用编号在
kernel/sysproc.c:到达sys_trace()函数,执行具体内核操作
这么繁琐的调用流程的主要目的是实现用户态和内核态的良好隔离。
System call tracing
接受一个参数mask指定需要追踪的系统调用,当指定的系统调用即将返回时打印一行信息(PID、该调用的名称、返回值),要追踪调用该命令的过程以及其后fork的所有子进程。
- 内核中获得参数的方法在
kernel/syscall.c中,有argint()、argaddr()等- 因为内核与用户进程的页表不同,寄存器也不互通,所以参数无法直接通过 C 语言参数的形式传过来,而是需要使用 arg 系列函数,从进程的 trapframe 中读取用户进程寄存器中的参数
- 所有的系统调用到达内核态后,都会进入到
syscall()这个函数进行处理,所以要跟踪所有的内核函数,只需要修改kernel/syscall.c的syscall()方法,实现最后的打印输出 - 系统调用编号 num 记录在
p->trapfram->a7,系统调用接口函数返回值记录在p->trapframe->a0
Sysinfo
写一个 sysinfo 这个system call,需要获取当前空闲的内存大小填入 struct sysinfo.freemem 中,获取当前所有不是 UNUSED 的进程数量填入 struct sysinfo.nproc 中,并将这个 struct 从内核空间传递到用户空间。
了解了在内核中空闲物理内存以怎样的方式组织起来
// run结构体就是一个指向自身的指针,用于指向下一个空闲页表开始位置 struct run { struct run *next; }; // 管理物理内存的结构 // 有一把锁lock保证访问时的互斥性 // 以及一个指向空闲页表的指针 struct { struct spinlock lock; struct run *freelist; } kmem;了解了
proc的状态。标准五状态进程模型中,进程分为New、Ready、Running、Waiting和Terminated五个状态,xv6除了多了标记进程块未被使用的UNUSED状态,与上述的五状态模型完全对应enum procstate { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };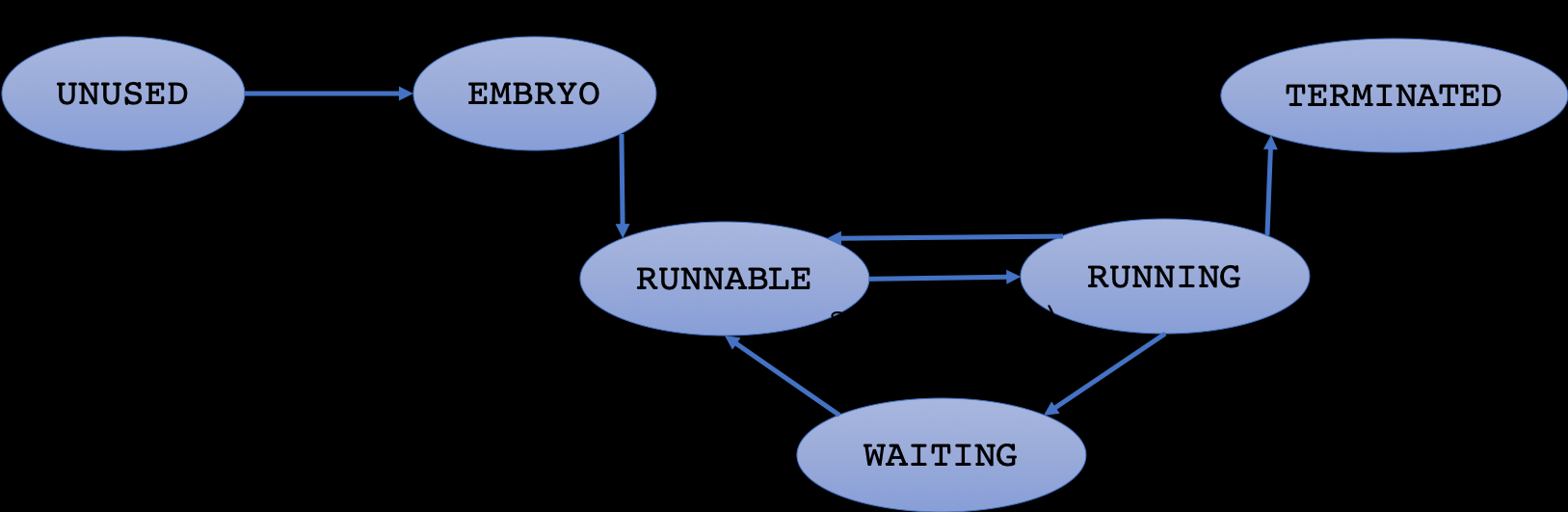
使用
copyout实现将数据从内核空间复制到用户空间int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)从 src 拷贝 len 长度的字节到 pagetable 页表的 dstva 位置处
Lab Page tables
XV6 运行于 Sv39 RISC-V 上,64 位地址中的低 39 位被使用。RISC-V 的页表逻辑上是 page table entries (PTEs) 的数组,长度为 2^27。PTE 包含 44 位物理地址号(PPN),页的大小为 4KB,因此,分页硬件使用 39 位中的高 27 位查找 PTE,之后转化为 56 位的物理地址。
实际上,RISC-V 使用的三级页表,1 级页表为 1 页(4KB),包含 512 个 PTE。27 位页号中的高 9 位为一级页表,中间 9 位为 2 级页表,末 9 位为三级页表。satp 给出了一级页表的基址。
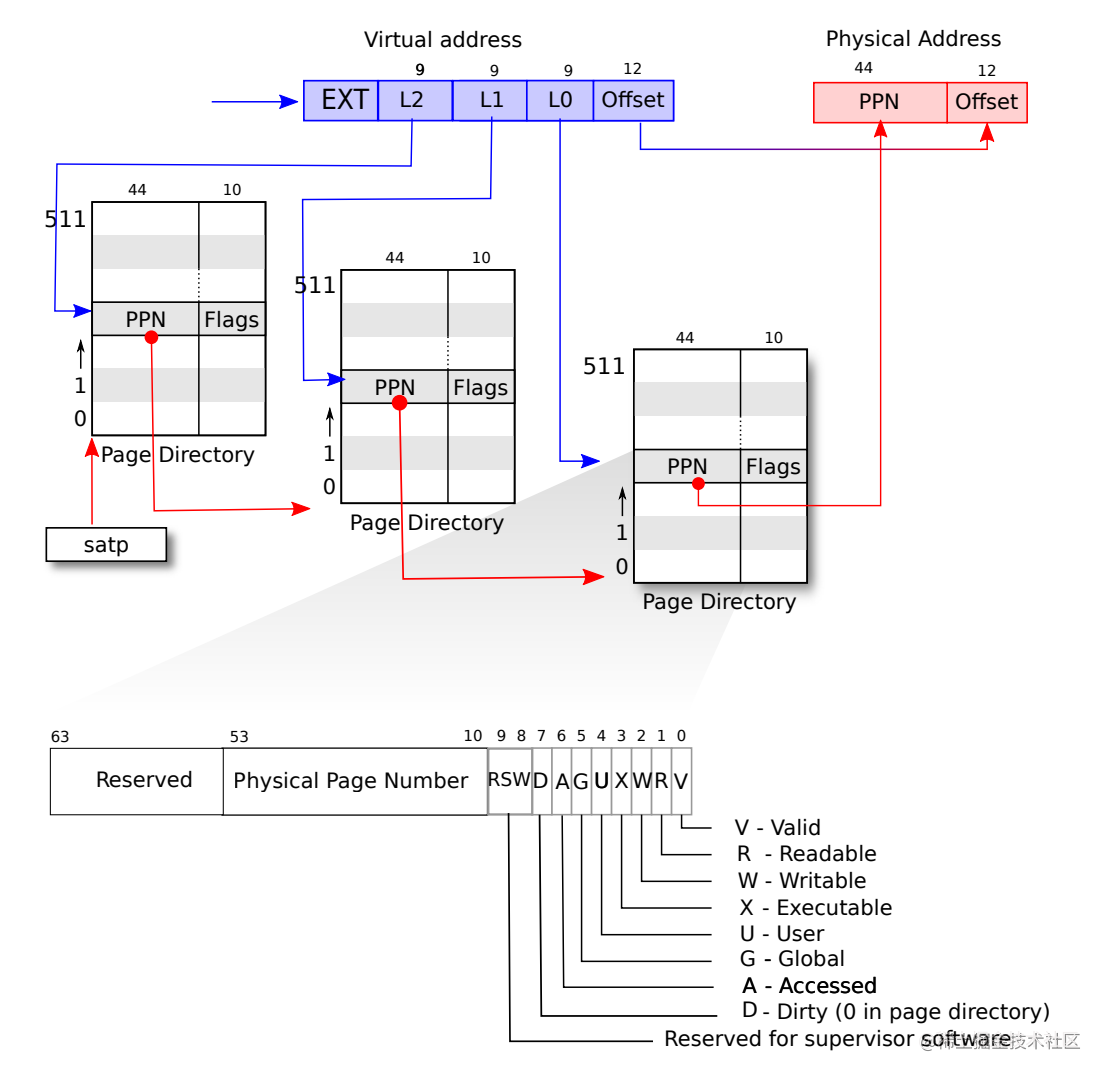
在 PTE 中,高 44 位为PPN,低 8 位为标志位。
Speed up system calls
为了加速系统调用,很多操作系统都会在用户空间内开辟一些只读的虚拟内存,内核会把一些数据分享在这里。这样就可以减少来回在用户态和内核态中切换的操作。该实验需要为系统调用 getpid() 实现这样的加速。
给
struct proc添加成员usyscall。xv6 通过调用
allocproc()函数创建一个新进程,找到了状态为UNUSED的进程后就对它做初始化工作,在分配完物理页后创建页表。在
allocproc()函数中添加为USYSCALL申请物理页,并初始化p->usyscall(pid)。proc_pagetable()的作用是创建一个新的用户页表,并在其中映射跳板代码和陷阱帧页,需要在这个函数中添加映射USYSCALL页。使用
mappages()函数将虚拟地址映射到物理地址,进程可以通过虚拟地址访问物理内存中的数据。int mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)uvmunmap()是取消从虚拟地址 va 开始的 npages 个页面的映射关系,do_free 可选是否需要是否物理内存。主要用来释放页表映射关系。void uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)对于本任务,标志位应该是
PTE_R | PTE_U,代表允许读,和允许用户访问。当需要获取进程的 PID 时,
getpid()可以直接从用户空间的USYSCALL虚拟地址中读取 PID,而不需要切换到内核态。
Print a page table
因为 xv6 的页表是三级的,所以是一个树的结构,那么本质上就是需要写一个dfs打印树的函数。
Detecting which pages have been accessed
实现函数 int pgaccess(void *base, int len, void *mask)。这个函数的主要作用就是检测从上次调用这个函数开始,页表是否被访问过。其中 base 参数是要检测的第一个页表,len 从这个页表开始,要检测多少个页表,而我们需要把每个页表的访问情况写到 mask 上,如果当前页表被访问,那么 mask 中对应的位应该是 1。
#define PTE_A (1L << 6),记录是否访问的位置是第六位。- 需要使用到
walk()函数,对于一个给定的页表和虚拟地址,walk()函数会返回对应这个虚拟地址的叶子 PTE,根据 PTE 判断访问情况以设置 mask 。
Lab Traps
Backtrace
对于调试,回溯跟踪通常很有用:在错误发生点上方的堆栈上调用函数的列表。这个实验在 kernel/printf.c 中实现 backtrace() 函数。并在 sys_sleep 中插入对此函数的调用。
- GCC 编译器将当前正在执行的函数的帧指针存储在寄存器 s0 中。可以通过在
kernel/riscv.h中添加以下函数获取其值:static inline uint64 r_fp() { uint64 x; asm volatile("mv %0, s0" : "=r" (x) ); return x; } - 编译器在每个堆栈帧中放置一个帧指针,该指针保存调用方帧指针的地址。
backtrace()应使用这些帧指针在堆栈中向上移动,并在每个堆栈帧中打印保存的返回地址。 - 返回地址位于与堆栈帧的帧指针的固定偏移量 (-8) 处,而上一个函数的帧指针保存于距当前帧指针的固定偏移量 (-16) 处。
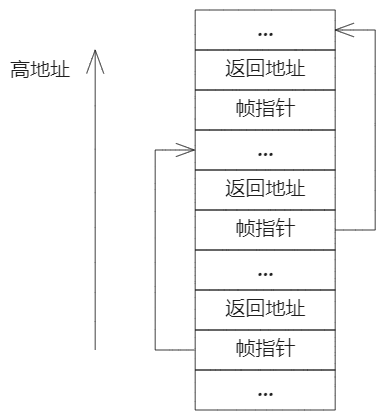
- 一连串的函数调用最多放在一个页中。
Alarm
在进程使用 CPU 时间时定期发出警报。添加一个新的 sigalarm(interval, handler) 系统调用,消耗每 interval 个 CPU 时间之后,内核应该导致应用程序函数 handler 被调用,返回时从中断的地方继续。此外还要实现一个 sigreturn() 系统调用,如果时间到了 handler 调用了 sigreturn() ,就应该停止执行 handler ,然后恢复正常的执行顺序。如果说 sigalarm 的两个参数都为 0,就代表停止执行 handler 函数。
p->trapframe->epc指出用户模式下要执行的下一条命令,通过设置这个寄存器可以导致应用程序函数handler被调用- 要执行
handler的时候,先备份一下环境然后再执行。p->trapframe就是用于用户态和内核态切换时上下文保护和恢复,所以新增成员alarmframe用于备份trapframe。 sigreturn()恢复现场时直接p->trapframe = p->alarmframe。
TODO
xv6的中断机制
Lab Copy on-write
xv6 中的 fork() 系统调用将父进程的所有用户空间内存复制到子进程中。如果父级很大,则复制可能需要很长时间,而且可能大部分的工作都被浪费。
采用写入时复制 (COW) fork() 来解决以上问题,推迟为子项分配和复制物理内存页,直到实际需要副本。
- COW fork() 只为子项创建一个页面表,用户内存的 PTE 指向父项的物理页面,将父级和子级中的所有用户 PTE 标记为不可写。
fork()使用uvmcopy()函数把父进程的内存和页表复制给子进程,修改该函数,只复制页表而不复制内存,使用mappages()函数设置新页表项指向相同的物理页面,并设置相应的权限标志
- 当任一进程尝试写入这些 COW 页面之一时,CPU 将强制出现页面错误。内核页面错误处理程序检测到这种情况,为错误进程分配一页物理内存,将原始页面复制到新页面中,并在错误过程中修改相关的 PTE 以引用新页面,这次将 PTE 标记为可写,并取消原来的映射。
- 需要判断错误是否在 COW 页上,因此需要有一种方法来记录是否是 COW 页。为此可以使用 RISC-V PTE 中的 RSW(为软件保留)位。
- 寄存器 scause 为 15 代表尝试写入引发的缺页错误。
- 给定的物理页可能被多个进程的页表引用,并且只有在最后一个引用消失时才应释放。
- PHYSTOP 和 KERNBASE 代表着内存物理地址的起始和结束
- 开一个全局数组记录每个页的引用次数,
kalloc()时将页面的引用计数设置为 1,kfree()时引用减 1,只有在其引用计数为零时才应将页面放回空闲列表,uvmcopy()中需要增加父进程页帧的引用计数
Lab Multithreading
Uthread: switching between threads
实现用户态多线程机制。
内核中线程切换
参考博客:xv6 中的进程切换:MIT6.s081/6.828 lectrue11:Scheduling 以及 Lab6 Thread 心得 - byFMH - 博客园 (cnblogs.com)
usertrap() 函数是 xv6 内核空间中的一个函数,如果有中断、异常、系统调用发生,就会跳转到这里,在这里进行进一步判断并且运行相应的处理程序。
//
// handle an interrupt, exception, or system call from user space.
// called from trampoline.S
//
void usertrap(void)
{
int which_dev = devintr(); // save user program counter.
struct proc *p = myproc();
// 由于中断发生时处于用户空间,而且中断发生时 PC-> SEPC,所以这里 p->trapframe->epc 被赋予了用户空间中某条指令的地址
p->trapframe->epc = r_sepc();
// some code ignore
// ...
// ...
// ...
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}RISC-V 中规定了如果是定时器中断 which_dev 的值会被置为 2,所以如果是定时器中断,就会运行函数 yield(),作用是该内核线程自愿地将 cpu 出让(yield)给线程调度器,并告诉线程调度器可以让一些其他的线程运行。
下面是 yield() 的实现,可以看到核心函数是 sched(),并且将旧线程的状态由 "RUNNING" 改为 "RUNABLE" ,将一个正在运行的线程转换成了一个当前不在运行但随时可以再运行的线程。
// Give up the CPU for one scheduling round.
void yield(void)
{
struct proc *p = myproc();
acquire(&p->lock);
p->state = RUNNABLE;
sched();
release(&p->lock);
}来看核心函数是 sched(),其中核心函数是 swtch()。
void sched(void)
{
// ignore some check code
// ...
// ...
// ...
struct proc *p = myproc();
swtch(&p->context, &mycpu()->context);
}swtch() 会保存用户进程P1对应内核线程的寄存器至P1的 context 对象。然后将 cpu 的 context 对象恢复到相应的寄存器中,因为需要直接和寄存器打交道,所以 swtch() 的代码是用汇编写的。
可以看到内核线程寄存器就是指 ra、sp、s0~s11 这 14 个寄存器。a0 寄存器对应着 swtch() 的第一个参数,也就是当前线程的 context 对象地址;a1 寄存器对应着 swtch() 的第二个参数,也就是即将要切换到的调度器线程的 context 对象地址。
# Save current registers in old. Load from new.
.globl swtch
swtch:
# 上半部分,将 14 个寄存器的值保存到当前线程的 context 对象中
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
# 下半部分,从 cpu 的 context 对象中恢复调度器线程的 14 个寄存器的值
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
# 指令 ret 被调用的时候,指令寄存器 pc 会被重置到 ra 所保存的地址。 经打印 ra 的值可以发现是返回到 scheduler 函数中
retscheduler() 也会调用 swtch() ,它属于调度器线程,而调度器线程是 xv6 系统启动的最后一环,随着 xv6 的启动而启动。
// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run.
// - swtch to start running that process.
// - eventually that process transfers control
// via swtch back to the scheduler.
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// ---------------特别注意,这里就是地址 0x80001f2e 处
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}线程调度的过程可以这样描述:
xv6 运行 P1 一段时间后,定时器中断被周期性触发,进程 P1 陷入内核态,在内核态中,保存公用寄存器(14 个)的状态到 P1->context 结构体中,然后恢复 cpu->context 结构体的数据到公用寄存器中,这样就把切换到了调度器线程,调度器线程会寻找一个进程状态为 RUNABLE 的进程(即 P2),将其状态修改为 RUNNING,然后调用 swtch 切换公用寄存器的状态为 P2->context,此时由调度器线程切换到 P2 的内核进程,接着返回到用户态,便完成了 P1->P2 的切换。
用户态线程切换
基本仿照内核态的线程切换来完成。
Using threads
可能出现多个线程同时操作同一个数据的话需要对这个数据上锁。
Barrier
同步屏障(Barrier)是并行计算中的一种同步方法。对于多个进程或线程,程序中的一个同步屏障意味着任何线程/进程执行到此后必须等待,直到所有线程/进程都到达此点才可继续执行下文。
Lab network driver
不太懂,要会看文档。
Lab Lock
Memory allocator
在原本的 kalloc() 中,只维护 freelist 链表,如果有任何程序申请内存,都需要竞争 freelist 的锁。
解决方法:每个处理器核心都分配一个 freelist。
难点:一个 CPU 的空闲列表为空,但另一个 CPU 的列表有空内存的情况。在这种情况下,一个 CPU 必须“窃取”另一个 CPU 的空闲列表的一部分。
Buffer cache
xv6 磁盘缓冲区中是使用一个如下图所示的LRU双向链表来维护:
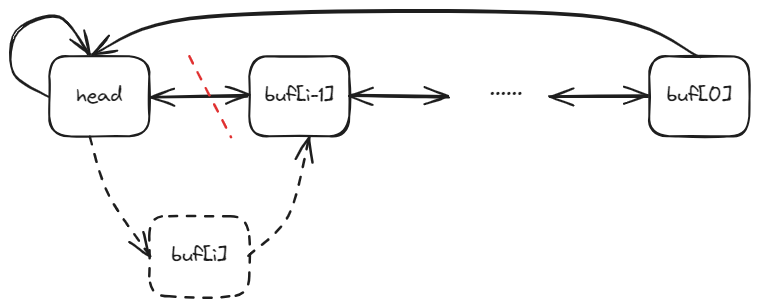
通过释放的时候将空闲的块移动到链表末尾来保证空闲块尽量在末端。
解决方法:实现一个哈希表。哈希表会把块号映射到块缓存的桶,那么只有两个进程试图操作同一个桶中的块缓存,才会造成竞争。而且在查找所需块缓存时只需要在对应的桶中查找。当然,在对应桶中没有足够缓存时,可以像在 kalloc() 中一样,从别的桶中偷缓存。
分成多个桶后没办法再用双向链表维护LRU,需要通过记录时间来找最久未用的块。
Lab File system
Large files
在 xv6 的底层实现中,文件是由 struct dinode 来描述的,如下:
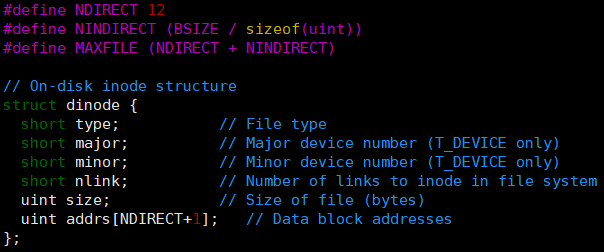
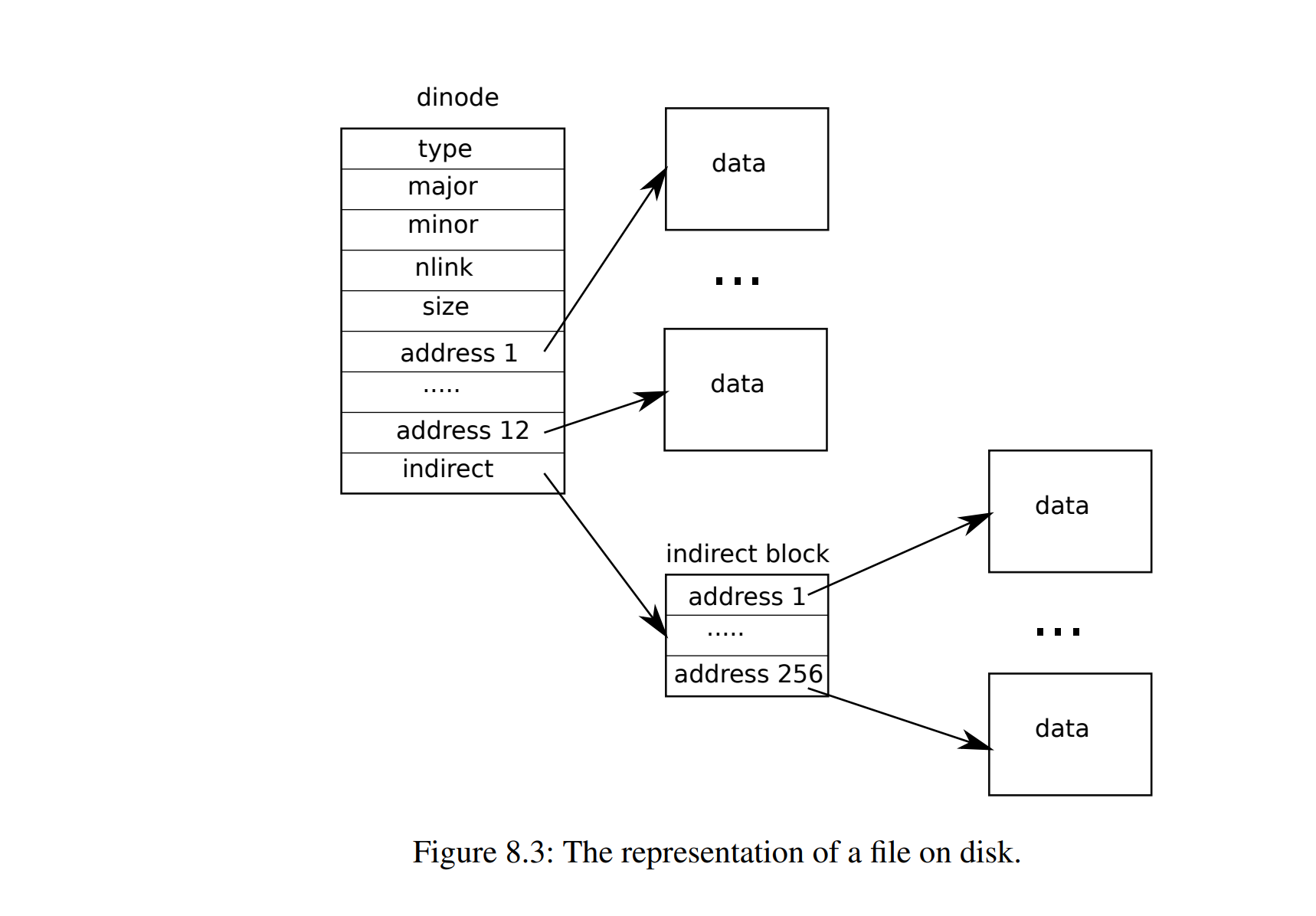
这里主要关注结构体中的 addrs 属性。其中有 addrs 的前十二个直接指向文件储存的块,最后一个是间接的块包含 256 个数据块地址,如下图所示:
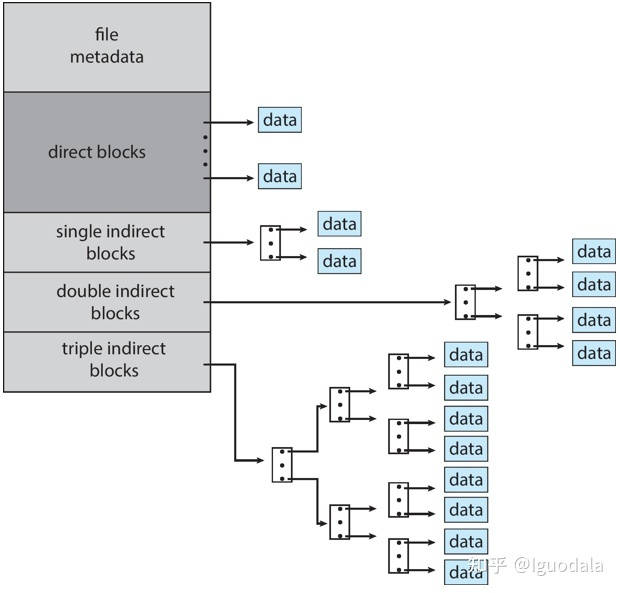
本任务目的是增加 xv6 文件的最大大小,根据任务描述需要修改 bmap() 使得 ip->addrs[] 的前 11 个元素为直接块,第 12 个是一个单间接块(就像现在的一样),而第 13 个应该是新的双重间接块。大致结构如下图所示:
对比两种方法,已知一个 struct dinode 有 64B 的大小,一个磁盘块能储存 1KB 的数据。
那么原本的方案可以文件的最大大小为 ;而改进后的方法,仅考虑这个二级间接块指针,它包含 256 个单间接块指针,每个地址最多可以包含 256 个数据块地址,所以总数就是 个块,即 64MB。
可以看出,这样的提升的非常大的。
Symbolic links
向 xv6 添加符号链接。符号链接(或软链接)通过路径名引用链接的文件;当打开符号链接时,内核会跟随链接到引用的文件。
软链接的本质其实是一个文件(即 inode),我们要在 inode 中储存此链接指向的文件的路径。为了实现链接的效果,在 open() 函数中,需要去根据链接中储存的路径,递归的找到最终指向的文件(可能会有一个软链接指向另一个软链接)。
硬链接是指在同一个文件系统中,将一个文件名关联到一个已经存在的文件上,使得该文件名也可以访问该文件。硬链接与原文件共享inode,即它们有相同的inode号和相同的device号。因此,对于硬链接和原文件来说,它们的访问权限、所有者、大小等属性都是相同的。硬链接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。
本质区别:
- 硬链接:同一个inode,只是多个名字。
- 软链接:是不同的文件,inode不同
Lab mmap
实现一个 UNIX 操作系统中常见系统调用 mmap() 和 munmap() 的子集。此系统调用会把文件映射到用户空间的内存,这样用户可以直接通过内存来修改和访问文件。
在 kernel/proc.h 定义 VMA(虚拟内存区域)的结构,记录 mmap 创建的虚拟内存范围的地址、长度、权限、文件等。还是使用懒分配,映射时不分配内存,缺页时再分配。
总体收获
还没组织好语言,有灵感了再写。。。
进程
内存的组织
页表机制
寄存器
中断机制
系统编程,如何使用C语言来编写系统级代码。
对于xv6的源码不够熟悉
不习惯gdb调试
这个方案是否是效率最高的,是否存在什么漏洞
有很多细节需要注意